Meta强化学习扩展定律研究:40万GPU小时揭示可预测训练与算力效率
Meta强化学习扩展定律突破:40万GPU小时揭示可预测训练与算力效率优化
在大语言模型领域,强化学习算力规模扩展正成为关键研究方向。然而,关于RL扩展定律仍存在几个核心问题亟待解决:如何有效扩展?哪些扩展方向具有实际价值?强化学习能否真正实现预期扩展效果?
为解答这些关键问题,Meta等研究机构展开了一项耗资巨大的实验:投入40万GPU小时计算资源,成功绘制出强化学习训练的"指导手册",使强化学习后训练过程从随机尝试转变为可预测的科学实践。

研究团队指出,当前强化学习进展主要来自特定算法的独立研究或个别模型训练报告,这些研究虽然提供了针对具体任务的解决方案,但缺乏随算力扩展的通用方法论。由于缺乏系统化扩展理论,研究进程严重受限:科研人员无法预先识别有前景的强化学习方案,只能依赖昂贵的大规模实验,导致大多数学术团队难以参与前沿研究。
本研究旨在建立强化学习扩展的科学基础,借鉴预训练阶段成熟的"扩展定律"概念。预训练领域已发展出随算力稳定扩展的算法范式,而强化学习领域尚未建立明确标准。强化学习研究者面临众多设计选择,却难以回答"如何扩展"和"扩展什么"这两个基础问题。

研究论文:The Art of Scaling Reinforcement Learning Compute for LLMs
论文链接:https://arxiv.org/pdf/2510.13786
为解决这一难题,研究团队提出了预测性框架,通过数学公式描述强化学习性能与算力关系:

具体而言,研究采用类sigmoid饱和曲线,将独立同分布验证集上的期望奖励与训练算力关联。参数A表示渐近性能上限,B代表算力效率,C_mid决定性能曲线中点。图3对这些参数进行了可视化解释。
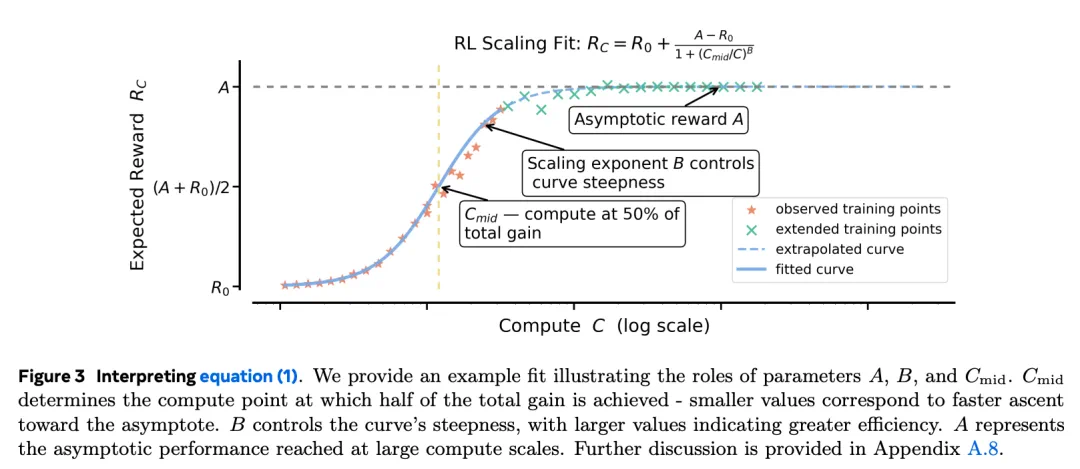
该框架使研究人员能够基于小规模实验结果预测更大算力下的表现,在不超过算力预算的前提下评估强化学习方法扩展性。
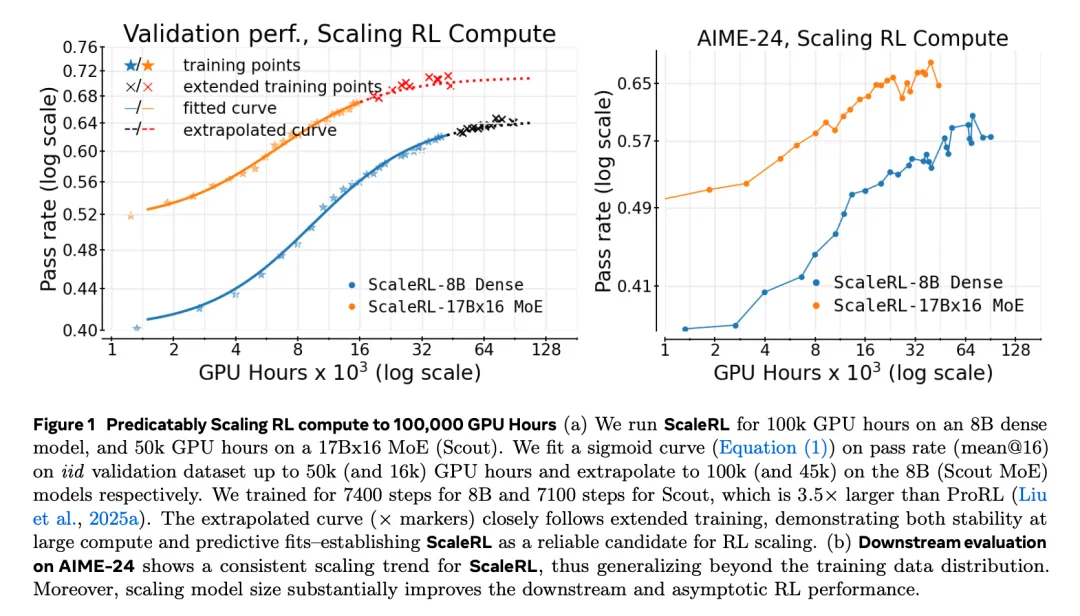
基于此框架,团队开发了ScaleRL——能够随算力可预测扩展的强化学习训练方案。在10万GPU小时的大规模实验中,ScaleRL表现与框架预测曲线高度吻合。更重要的是,仅使用训练初期数据外推的曲线也能准确预测最终性能,证明框架在极大算力下的预测能力。
ScaleRL设计基于超过40万GPU小时的系统实证研究,在Nvidia GB200 GPU上使用8B参数模型探索多种设计选择。研究总结出三条关键原则:
性能上限非普适性:不同方法在算力扩展时遇到不同性能天花板,可通过损失函数类型、批次大小等设计调整上限
接受"苦涩教训":小算力下优秀的方法在大规模算力时可能表现更差,通过训练早期估计参数可识别真正可扩展方法
重新评估常见经验:许多被认为提升峰值性能的技巧主要影响算力效率,而非最终性能上限
基于这些洞察,ScaleRL整合现有成熟方法实现可预测扩展,包含异步Pipeline-RL结构、生成长度中断机制、截断重要性采样RL损失、基于提示的损失平均、批次级优势归一化、FP32精度logits、零方差过滤和No-Positive-Resampling策略。每个组件通过"留一法"消融实验验证。
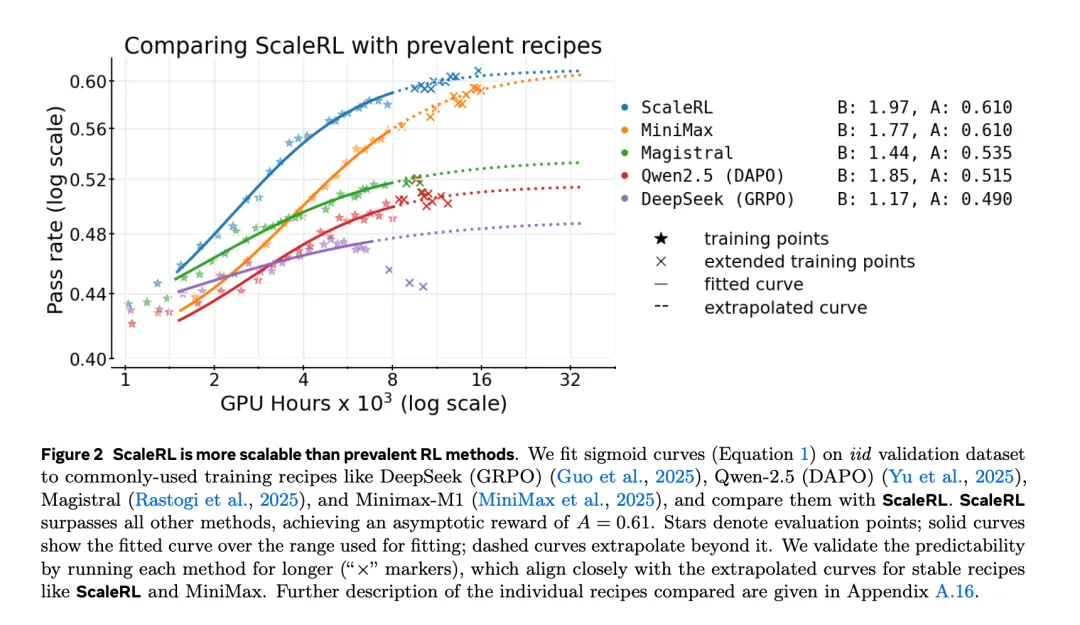
ScaleRL不仅稳定扩展,在性能与效率上均超越现有强化学习方案。当在多个训练维度增加算力时,ScaleRL保持预测一致性并持续提升下游任务表现。本研究建立了严谨、可量化方法论,使研究人员能以更可控成本预测新强化学习算法扩展性。
该论文是首个关于大语言模型强化学习扩展的开源大规模系统研究,内容详实、结论具有重要参考价值,受到Ai2科学家Nathan Lambert等专家强烈推荐。
想获取更多AI最新资讯与智能工具推荐, 欢迎访问 👉 AI Tools Nav ——优质的 AI导航平台 与 AI学习社区
本文来源:机器之心
原文链接:https://www.jiqizhixin.com/articles/de192bce-e836-4d87-a133-e0b8091e21aa





