空间智能再进化:Spatial-SSRL与LVLM推动自监督强化学习下的空间理解
空间智能新突破:Spatial-SSRL与LVLM引领自监督强化学习的空间认知革命

作者信息:本文第一作者刘禹宏为上海交通大学人工智能专业大四学生,研究工作在上海人工智能实验室实习期间完成。通讯作者为王佳琦、臧宇航,均为上海人工智能实验室研究员。
近年来,视觉大语言模型(LVLM)的空间智能能力日益受到学界重视,卓越的空间理解技术对自动驾驶、具身智能等前沿领域发展至关重要。然而,现有LVLM在空间认知方面仍与人类水平存在明显差距。
近期,上海人工智能实验室联合上海交通大学、香港中文大学等顶尖机构的研究团队,创新性地提出了名为Spatial-SSRL(自监督强化学习)的全新训练范式。这一突破性方法完全无需外部标注,专注于提升LVLM的空间理解性能。实验结果显示,该范式在Qwen2.5-VL(3B和7B)及最新Qwen3-VL(4B)架构中均显著增强了模型的空间认知能力,同时完美保持了原有的通用视觉功能。
目前,Spatial-SSRL在Huggingface平台的模型和数据集总下载量已突破千次,诚邀各界研究者下载体验!

- 论文地址:https://arxiv.org/pdf/2510.27606
- 代码仓库:https://github.com/InternLM/Spatial-SSRL
- 模型下载:https://huggingface.co/internlm/Spatial-SSRL-7B
- 补充模型:https://huggingface.co/internlm/Spatial-SSRL-Qwen3VL-4B
- 数据集:https://huggingface.co/datasets/internlm/Spatial-SSRL-81k
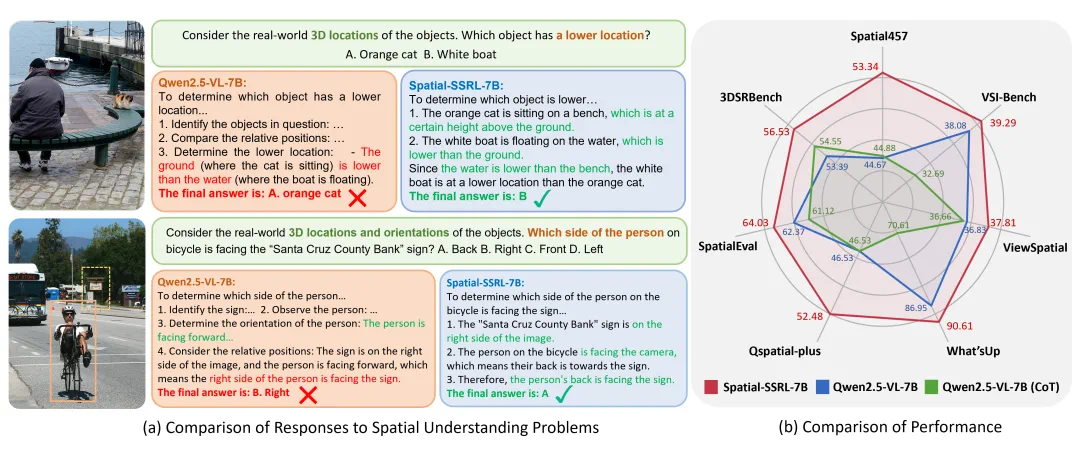
图1. Spatial-SSRL效果展示与性能评估
研究背景深度解析
传统提升LVLM空间理解能力的方法主要依赖监督微调(SFT)技术。这种方法需要包含思维链(CoT)标注的训练数据,往往需要大量人工标注或依赖闭源模型,成本高昂且扩展性有限。此外,SFT优化后的模型容易出现"机械记忆"现象,泛化能力较弱。
基于可验证奖励的强化学习(RLVR)逐渐成为新的主流训练范式。如图2(a)所示,现有基于RLVR的空间理解方法通常需要构建复杂的数据处理流程,依赖已标注的公开数据集和多种外部工具(如专家模型、模拟器等),框架繁琐且引入额外的计算开销。
RGB和RGB-D图像本身蕴含丰富的2D和3D空间信息,可作为天然的视觉监督信号。基于这一洞察,研究团队提出了自监督强化学习新范式,实现了低成本、高效率的LVLM空间理解能力提升。
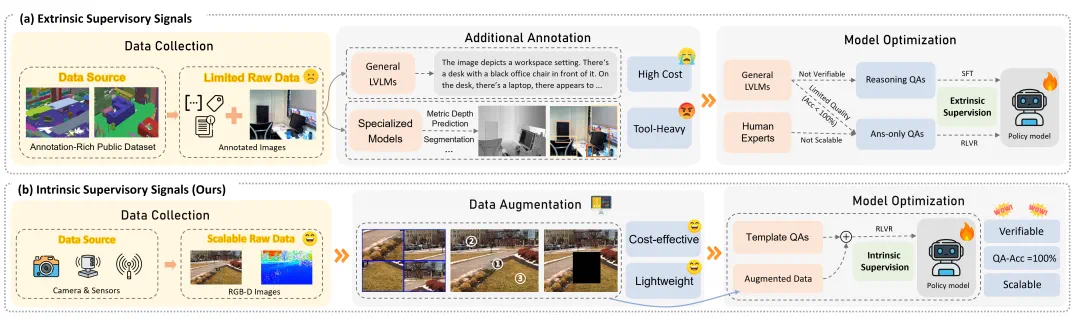
图2. Spatial-SSRL与现有技术框架对比分析
核心方法与技术亮点
Spatial-SSRL基于易获取的RGB和RGB-D图像,设计了五种自监督学习任务:图块重排序、翻转识别、裁剪复原、深度排序和3D位置预测。这些任务充分利用视觉线索作为监督信号,分别针对2D布局理解、物体朝向识别、3D深度与位置关系等空间认知维度,形成互补,全方位提升空间理解能力。

图3. Spatial-SSRL方法体系总览
相较于传统方法,Spatial-SSRL展现出四大核心优势(如图2(b)所示):
- 卓越的可扩展性:仅使用常见的RGB和RGB-D原始图像,无需任何标注数据或人工标注,在数据规模上具备极强扩展潜力
- 显著的成本优势:整个训练流程无需人工干预或调用LVLM API,数据标注完全自动化,大幅降低开发成本
- 轻量高效架构:摆脱对外部工具的依赖,避免训练误差引入,减少时间和计算资源消耗,支持快速扩展到更多自监督任务
- 天然验证机制:利用图像固有结构作为内在监督信号,正确率接近完美,直接生成可验证奖励,与RLVR范式高度契合
研究团队基于上述流程构建了Spatial-SSRL-81k数据集,并采用GRPO方法进行训练,有效引导模型输出推理过程,显著提升空间理解能力。
实验结果与分析
为全面验证Spatial-SSRL范式的有效性,研究团队选取了Qwen2.5-VL(3B和7B)和Qwen3-VL(4B)三个不同规模的基模型,使用GRPO进行训练,并对训练后模型进行了空间理解和通用视觉能力的全方位评估。
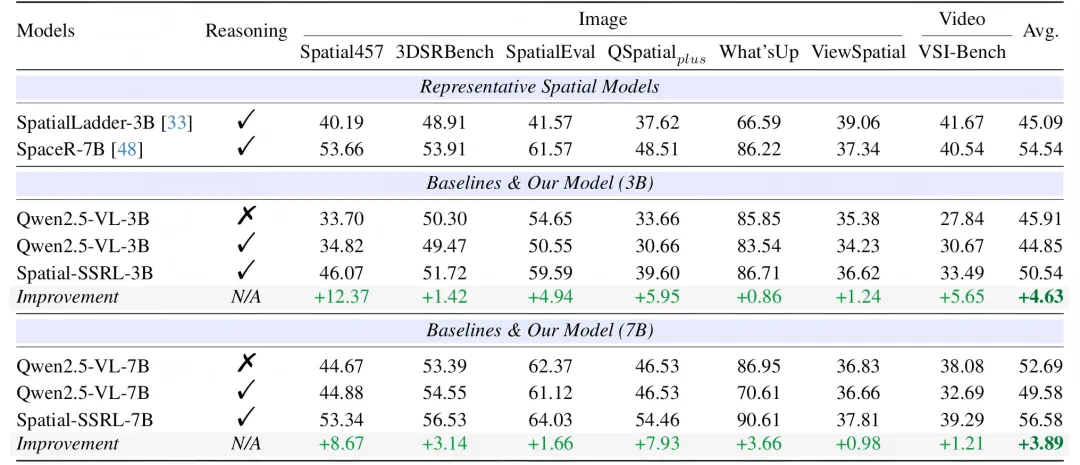
图4. 训练前后模型空间理解性能对比(Qwen2.5-VL架构)
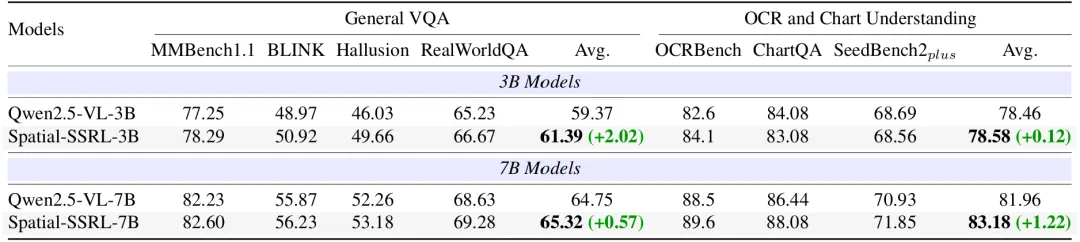
图5. 训练前后模型通用视觉能力对比(Qwen2.5-VL架构)
从图4和图6可以明显看出,在Qwen2.5-VL和Qwen3-VL两种架构的三个不同参数规模下,Spatial-SSRL均显著提升了LVLM的空间理解能力,在全部7个空间基准测试(涵盖图像和视频两种模态)中均取得进步。其中,7B模型平均性能超越基线3.89%,3B模型提升幅度达到4.63%,充分证明了Spatial-SSRL自监督RL范式的有效性和鲁棒性。
针对模型通用能力保持的关切,研究人员进一步评估了训练前后模型的通用视觉能力。在通用视觉问答以及OCR与图表理解两大类基准测试中,模型的通用视觉能力基本保持稳定,平均表现甚至略有提升,证明Spatial-SSRL不会导致模型"技能遗忘"。
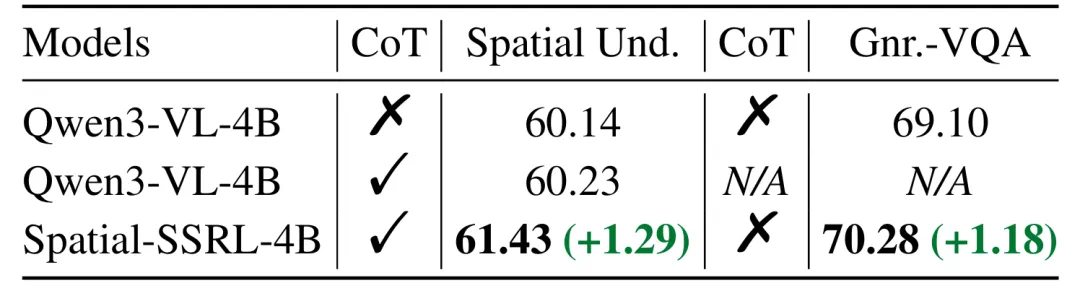
图6. 训练前后模型性能对比(Qwen3-VL架构)
技术总结与展望
Spatial-SSRL开创了一种直接从图像内在结构中生成可验证监督信号的自监督强化学习新范式。其核心创新在于能够从易获取、低成本的RGB与RGB-D图像中直接提取丰富的空间理解自监督信号,这些信号通过可验证奖励机制与强化学习完美融合。
在七个空间基准上的全面实验证明,Spatial-SSRL带来了显著的空间理解提升,在复杂空间推理任务中表现尤为突出。更重要的是,Spatial-SSRL在增强空间能力的同时,完整保持了模型的细粒度感知和通用视觉理解能力。这一突破表明,简单的内在视觉监督信号能够有效实现大规模RLVR,为未来提升LVLM空间智能开辟了全新的技术路径!
目前,该研究的代码、模型和数据集已全面开源,欢迎广大研究者和开发者下载体验!
想获取更多AI最新资讯与智能工具推荐, 欢迎访问 👉 AI Tools Nav ——优质的 AI导航平台 与 AI学习社区
本文来源:机器之心
原文链接:https://www.jiqizhixin.com/articles/36d8cd9a-ab37-4bb7-bdad-ab009a61738f





