Self-Forcing++突破4分钟长视频生成,自回归扩散模型实现高质量输出
Self-Forcing++:突破4分钟长视频生成壁垒,自回归扩散模型实现高质量持续输出
本项突破性研究由加州大学洛杉矶分校与字节跳动Seed团队等顶尖机构联合完成。
在扩散模型持续推动视觉生成技术发展的今天,图像生成已臻至成熟境界,然而视频生成领域仍面临着一个关键的技术瓶颈——生成时长限制。当前大多数模型仅能生成数秒时长的短视频片段,而Self-Forcing++技术首次将视频生成推进到4分钟高质量长视频时代,且无需依赖任何长视频数据进行再训练。以下是该技术生成的100秒视频展示:

研究资源
- 论文标题:Self-Forcing++: Towards Minute-Scale High-Quality Video Generation
- 论文地址:https://arxiv.org/abs/2510.02283
- 项目主页:https://self-forcing-plus-plus.github.io
- 开源代码:https://github.com/justincui03/Self-Forcing-Plus-Plus
技术挑战:长视频生成的深层困境
在扩散模型驱动的视觉生成领域,从Sora、Wan、Hunyuan-Video到Veo,视频生成模型正不断逼近真实世界表现。然而几乎所有主流模型都存在一个共同的技术限制:仅能生成数秒时长的短视频片段。
这一限制源于架构层面的根本性挑战:
- Transformer的非因果特性——传统扩散Transformer需要同时处理所有帧数据,无法实现自然的逐帧扩展
- 训练与推理阶段的不匹配——模型训练仅接触5秒短片,推理时却要生成几十秒甚至数分钟内容
- 误差累积效应——教师模型在单帧提供强监督,但学生模型缺乏应对长序列中逐步误差的能力
- 过曝光与画面冻结——长时间生成后常出现画面静止、亮度漂移、运动中断等灾难性质量崩塌
这些技术难题共同导致:即使是最先进的自回归视频扩散模型,也难以在10秒以上保持画面一致性与运动连贯性。
核心创新:教师模型作为世界模拟器
Self-Forcing++的关键技术洞察在于:
教师模型虽然仅能生成5秒视频,但依然具备纠正长视频失真的强大能力。
研究团队巧妙利用这一特性,让学生模型先生成长视频内容(即使这些视频已开始出现质量崩坏),再利用教师模型纠正其中的错误。
通过这种「生成→失真→纠错→学习」的循环机制,模型逐步掌握了在长时间尺度下自我修复和稳定生成的能力。这一创新机制使Self-Forcing++无需任何长视频标注数据,就能将生成时长从5秒扩展到100秒,甚至达到4分钟15秒(接近位置编码极限的99.9%)。
技术解析:实现稳定超长视频生成的三步法

1️⃣ 反向噪声初始化技术
传统短视频蒸馏中,模型每次均从随机噪声开始生成。Self-Forcing++创新性地在长视频展开后,将噪声重新注入已生成序列,确保后续帧与前文保持时间连续性。这一步骤相当于让模型「重启而不失忆」,有效避免时间割裂问题。
2️⃣ 扩展分布匹配蒸馏
研究团队将原本局限于5秒窗口的教师-学生分布对齐,扩展为滑动窗口蒸馏机制:
学生模型生成100秒长视频 → 随机抽取任意5秒片段 → 利用教师分布校正该片段
这种设计使教师模型无需生成长视频,也能通过「局部监督」指导学生模型的长序列表现,实现长期一致性学习。
3️⃣ 滚动KV缓存机制
以往自回归模型在推理时使用滚动缓存,但训练阶段仍采用固定窗口,造成严重性能偏差。Self-Forcing++在训练阶段同步采用滚动缓存,实现真正的训练-推理对齐,彻底消除「曝光漂移」和「帧重复」问题。
进阶优化:强化学习赋能时间平滑
在部分极长视频场景中,模型仍可能出现突然跳帧或场景突变。研究团队借鉴强化学习中的Group Relative Policy Optimization框架,引入光流平滑奖励机制,让模型通过惩罚光流突变来学习更自然的运动过渡。实验结果显示:光流方差显著下降,视频流畅度大幅提升。
实验结果:全面超越基线模型的性能表现
📊 测试环境配置
- 模型规模:1.3B参数(与Wan2.1-T2V相同)
- 对比方法:CausVid、SkyReels-V2、MAGI-1、Self-Forcing等
- 评估指标:VBench + 新提出的视觉稳定性指标
📈 核心性能成果
以下数据展示在VBench和Gemini-2.5-pro视觉稳定性测试中的综合表现:
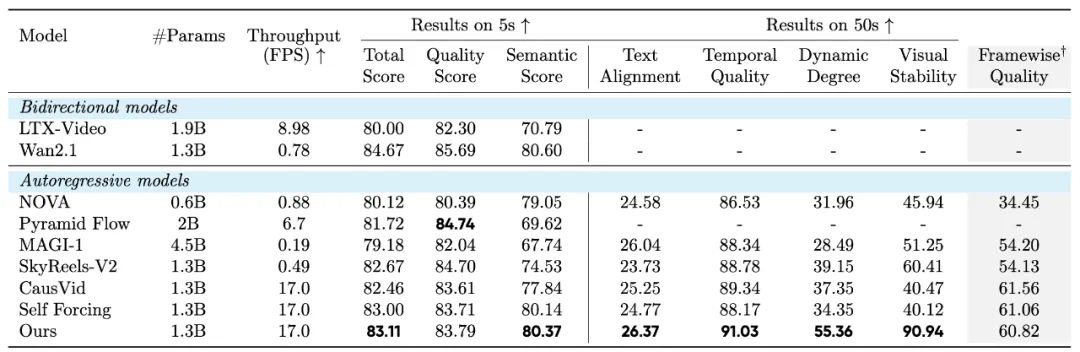
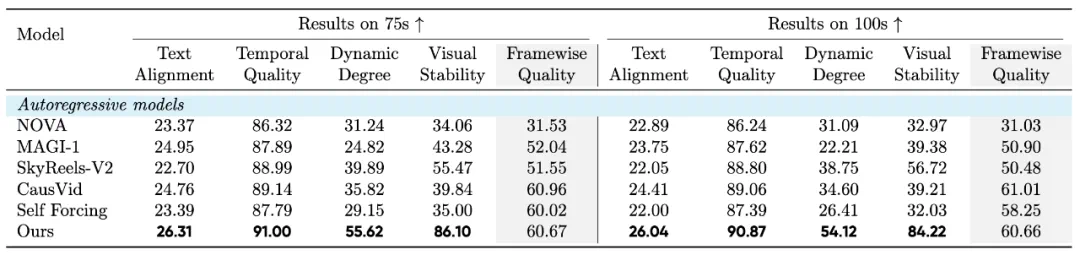
如下图所示,在0-100秒的生成时间范围内,Self-Forcing++始终保持卓越的稳定性,而基线模型大多经历严重的质量下降,包括过曝光和错误累积等问题。

视觉展示:超长视频生成效果


在这些长视频生成示例中,Self-Forcing++始终保持稳定的亮度控制和自然的运动表现,视觉质量几乎无明显劣化。
扩展现象:算力与生成时长的正向关系
研究团队进一步探索「计算资源与生成时长」的关联性,在可视化生成过程中获得重要发现:
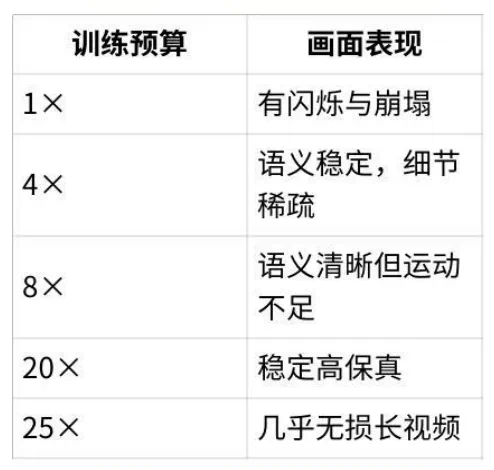
这一发现表明:无需长视频训练数据,仅通过扩展训练计算预算,即可有效延长视频生成时长。
技术局限与未来展望
尽管自回归视频生成已达到分钟级别,但以下技术挑战仍需进一步突破:
- 长期记忆缺失:在极长场景生成中,仍可能丢失被遮挡物体的状态信息
- 训练效率优化:自回归训练计算成本较高,相比teacher-forcing训练速度仍有提升空间
更多技术演示视频和详细方法说明请访问项目主页。
想获取更多AI最新资讯与智能工具推荐, 欢迎访问 👉 AI Tools Nav ——优质的 AI导航平台 与 AI学习社区
本文来源:机器之心
原文链接:https://www.jiqizhixin.com/articles/02bc6568-bad8-4a5d-97a6-b09d8c10bbb3





