HumanLift单图重建三维数字人,高斯网多视角生成高保真
HumanLift:单图重建三维数字人,高斯网技术实现高保真生成

在当今数字化时代,创建具有高度真实感的三维数字人已成为影视制作、游戏开发和虚拟现实/增强现实(VR/AR)等领域的核心技术需求。这项技术不仅能够提升视觉体验的真实度,还能为各类数字应用注入更丰富的交互可能性。
虽然现有技术在多视角图像重建高质量、可动画化的三维人体模型方面取得了显著进展,但从单张参考图像重建真实感三维数字人仍然面临诸多技术瓶颈。这一过程不仅技术复杂度高,还需要消耗大量计算资源。
当前技术面临的核心挑战包括:如何在保持三维一致性的同时确保与参考图像的一致性,如何重建出高质量、高真实感的人物外观与姿势,以及如何生成细节一致的高真实度服饰和人脸特征。
近期,来自中国科学院计算技术研究所、香港科技大学和英国卡迪夫大学的研究团队联合提出了一项突破性技术——HumanLift。这项基于单张参考图像重建高斯网(GaussianMesh)数字人全身的创新方法,其相关技术论文已被SIGGRAPH ASIA 2025接收。

- 项目主页:http://geometrylearning.com/HumanLift/
HumanLift提出了一种融合三维视频扩散模型和人脸增强的单图高斯网数字人重建方案。用户仅需输入单张人体图片,即可重建出高质量、高逼真度的三维数字人。该技术不仅能在不可见视角下准确估计人物外观和服饰几何细节,还能保持多视角一致性,同时确保生成的三维模型符合参考图像中的先验信息。
下图展示了基于单张参考图像重建数字人方法的效果:
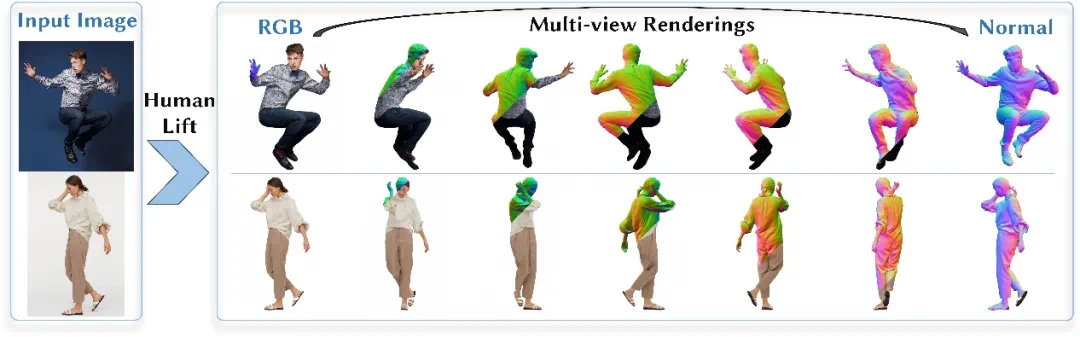
图1 基于单张参考图像重建三维高斯网(GaussianMesh)数字人结果
技术背景与发展历程
早期的单图数字人重建方法主要分为显式与隐式两大类。显式方法通常依赖参数化模型,能够对人体基础形状进行有效估计,但由于模板结构固定,难以处理复杂衣着情况。隐式方法则通过隐式函数描述复杂几何,虽然在重建质量上有所提升,但往往计算成本较高,且因缺乏有效先验,生成纹理的真实感仍面临挑战。
近年来,随着生成模型(如Stable Diffusion)和神经隐式渲染方法(如神经辐射场NeRF、三维高斯泼溅3D-GS)的快速发展,二维图像与三维空间之间的联系得以快速构建,使得二维生成能力能够有效助力三维内容生成。
尽管已有研究在一般物体的单视图三维重建方面取得显著进展,但由于三维人体数据稀缺以及人物姿势、服饰的复杂性,将这些方法拓展到高真实感三维人体建模领域仍面临诸多困难。
部分方法尝试从参考图片提取文本信息,并借助扩散模型与可微渲染技术进行建模,但受文本条件模糊性限制,难以准确还原精细服装细节,且优化效率较低。随着多视图扩散生成技术的发展,研究者开始探索从单图直接生成多视图人体图像,以规避复杂优化流程。
例如,将多视图生成与3D高斯泼溅(3D-GS)结合为统一优化模块,然而这类方法因缺乏三维先验,导致视角不一致问题。另一些方法则引入显式三维人体先验,结合生成模型以提升多视图一致性,虽然在服装与姿态的真实性上有所提升,但由于面部在全身图中占比过小,仍存在面部细节缺失、一致性与真实感不足的问题。
算法原理与技术实现
HumanLift的核心目标是:给定一张人物单张图像,创建一个能够捕捉逼真外观和细微细节(如服装纹理)的3D数字形象,同时包含清晰的人脸细节,实现自由视角浏览。该方法通过两个精心设计的阶段完成这一任务。
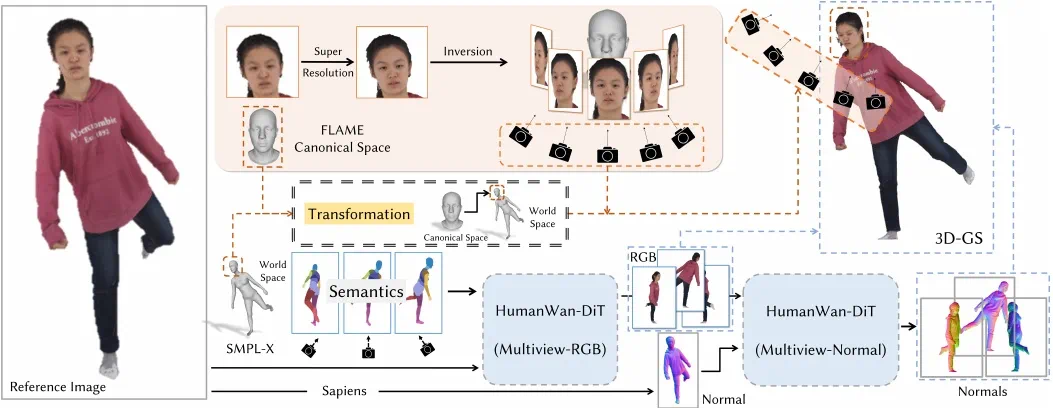
图2 HumanLift的方法框架图
第一阶段:多视角图像生成
此阶段旨在从一张日常拍摄的个人照片中生成逼真的多视角图像。HumanLift设计了一种具备3D感知能力的多视角人体生成方法。
为了确保对一般图像的泛化能力,生成器的骨干网络基于当前先进的视频生成模型Wan2.1构建——该模型在大量2D通用视频上完成训练,具备强大的高保真视频推断能力。HumanLift基于该模型并引入额外的三维人体先验,处理2D人体动画任务,并继承其预训练权重。
具体而言,该阶段设计了两种专门针对人体优化的模型——HumanWan-DiT(RGB)和HumanWan-DiT(Normal),以增强不同视角的一致性和几何细节。
同时,引入SMPL-X的多视角语义图像作为3D先验条件,并将其嵌入到Wan2.1中,提供3D引导。为了减少训练内存开销的同时保持模型生成能力,方法采用低秩适应(LoRA)技术进行内存高效的参数微调。
此外,通过一个由堆叠3D卷积层组成的轻量条件编码器,对人体的三维先验信息进行编码。
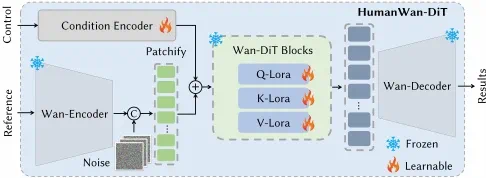
图3 HumanWan-DiT网络架构
其中:
- HumanWan-DiT(RGB):以SMPL-X的语义图像为条件输入,以人全身的RGB图片为参考输入,最终输出人体多视角的RGB图像;
- HumanWan-DiT(Normal):以HumanWan-DiT(RGB)生成的多视角图像为条件输入,以人预测的法向图片为参考输入,最终输出多视角的法向图像。
第二阶段:3D-GS模型重建
该阶段利用第一阶段生成的多视角图像,包括多视角的Normal图片和RGB图片,重建人体的3D-GS表示。
首先,该方法借助现有生成模型对超分辨率的面部图像进行多视角图片生成,生成具有标准空间下相机姿态的高质量多视角面部图像。
在重建过程中,以生成的多视角人脸图像和第一阶段生成的多视角人体图像作为监督信号,基于高斯网表示(GaussianMesh)对三维高斯球的参数进行优化。
需要特别注意的是,为确保面部渲染的准确性,需将面部图像的相机姿态(标准空间)转换到SMPL-X头部(世界空间),以监督面部部分的高斯球属性,获得高质量的人脸细节。
由于初始的SMPL-X与人体的3D-GS的位置上存在误差,HumanLift会根据每次迭代优化后的SMPL-X的姿态参数,从而动态调整面部相机姿态,确保面部相机姿态与头部的3D高斯球始终保持一致。
技术效果与性能展示
真实环境人体图片重建数字人
为展示HumanLift在真实拍摄人物图片中的效果,对于每张参考图像,该方法可以预测多视角的RGB图片和Normal图片。
实验结果表明,HumanLift生成的多视角RGB图像具有照片级真实感,多视角法向图能精准反映人物及服饰的几何细节,且整体保持了良好的空间一致性。
为进一步展示HumanLift的泛化能力,图4呈现了更多人物的重建结果,包括不同服饰风格、不同拍摄场景下的人物案例。无论参考图像的人物特征、服饰类型,HumanLift均能稳定生成高质量、高一致性的三维数字人。

图4 不同服饰和衣物下的颜色和法向结果
消融实验验证
为验证各模块的作用,图5展示了HumanLift的消融实验结果,即对三种消融方法(禁用面部增强、禁用SMPL-X姿态优化和禁用人体多视角法线图监督)的定性对比分析结果:
- 禁用面部增强:面部细节明显缺失,真实感大幅下降;
- 禁用SMPL-X姿态优化:人体姿态与头部相机位姿匹配度降低,头部渲染效果偏离真实场景;
- 禁用人体多视角法线图监督:服饰细节丢失严重,几何结构呈现不准确。
消融实验结果证明,面部增强模块通过生成先验显著提升面部细节质量;SMPL-X优化模块不仅能有效调整人体姿态参数,还能同步更新头部相机位姿,引导3D-GS模型生成更符合真实感的头部渲染效果;基于微调HumanWan-DiT(Normal)模型提供的法线监督,能让3D-GS表征在多视角一致法线图像的指导下,更好地保留衣物细节。

图5 不同策略下的消融结果
技术总结与展望
随着大模型和生成式人工智能的快速发展,单图全身数字人重建问题迎来了全新的解决范式。传统重建方法存在渲染结果真实感不足、复杂衣物和姿势难以精准重建等问题;而现有生成式方法,也难以在人物姿势、服饰细节和人脸真实感与一致性重建之间实现完美平衡。
HumanLift提出了一种有效的解决方案,通过微调基于三维扩散先验的视频生成模型和专门设计的人脸增强模块。借助该方法,用户无需进行繁琐的数据处理,仅需输入单张参考图片,就能重建出高质量、高逼真度的三维数字人——不仅能在新视角下准确估计人物外观和服饰几何,还能保持多视角一致性,同时确保生成的三维模型符合输入图像中的人物信息。
这项技术的突破为数字内容创作、虚拟现实应用和影视特效制作等领域带来了新的可能性,标志着单图三维数字人重建技术迈入了新的发展阶段。
想获取更多AI最新资讯与智能工具推荐, 欢迎访问 👉 AI Tools Nav ——优质的 AI导航平台 与 AI学习社区
本文来源:机器之心
原文链接:https://www.jiqizhixin.com/articles/4b1675f2-3f5c-4dba-b7ff-b6748c420880





