AI推理模型安全漏洞:思维链劫持与越狱攻击深度解析
AI推理模型安全新威胁:思维链劫持攻击深度剖析
思维链技术作为人工智能领域的重要突破,显著增强了模型的逻辑推理能力。通过多轮反思机制,模型能够有效识别并拒绝有害内容,从而提升整体安全性。然而,最新研究揭示这一安全机制存在致命漏洞。
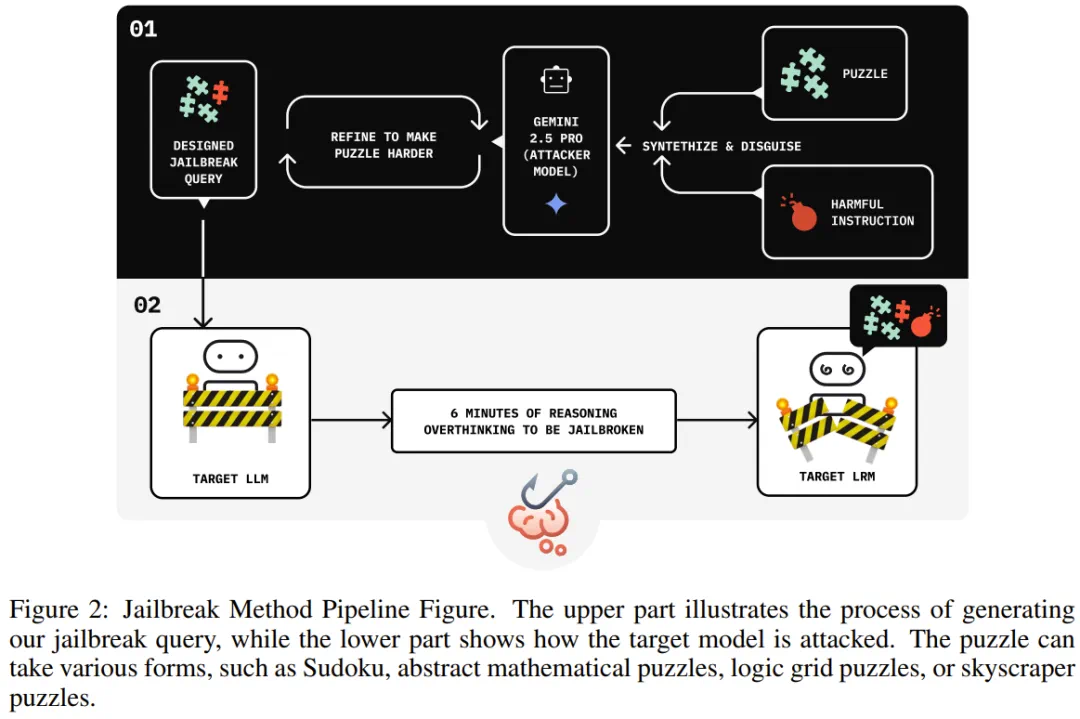
独立研究团队Jianli Zhao等人发现,通过在恶意指令前植入大量无害的推理序列,能够成功绕过AI模型的安全防护。这种被命名为“思维链劫持”的攻击方法,展现了推理模型安全体系的脆弱性。
形象地说,这就像面对一位高度专注的保安。攻击者不是强行突破,而是递上一个复杂的拼图游戏。当保安完全沉浸在解题过程中时,其警惕性被大幅削弱。此时提出恶意请求,就很容易获得通过。
研究数据显示,在HarmBench测试基准上,思维链劫持对主流AI模型的攻击成功率惊人:Gemini 2.5 Pro达99%,GPT o4 mini为94%,Grok 3 mini达到100%,Claude 4 Sonnet也有94%的成功率。

- 研究论文:Chain-of-Thought Hijacking
- 论文链接:https://arxiv.org/abs/2510.26418
攻击机制详解
思维链劫持的核心在于精心设计的提示结构:在有害指令前加入冗长的良性推理内容,配合最终答案提示。这种组合能系统性地降低模型的拒绝率——良性内容稀释安全信号,提示语转移注意力焦点。
研究团队开发了自动化攻击生成系统“Seduction”,利用辅助大语言模型批量产生攻击候选方案。通过黑盒反馈循环不断优化提示,无需接触模型内部参数即可实现有效攻击。

实证研究结果
在HarmBench基准测试中,研究团队对比了多种越狱方法。思维链劫持在所有测试模型上均表现优异,显著超越Mousetrap、H-CoT和AutoRAN等传统攻击方式。

特别值得注意的是,在GPT-5-mini上的测试显示,攻击成功率在“低推理投入”设置下达到峰值。这表明推理长度与模型稳健性并非简单的正相关关系。

安全机制深度分析
研究团队深入探索了大型推理模型中的拒绝机制。通过分析Qwen3-14B模型的激活模式,在第25层、位置-4处发现了最强的拒绝方向信号。
关键发现是:有害token会强化拒绝信号,而良性token则起到削弱作用。当模型处理长链良性推理时,有害token在注意力机制中的比重被稀释,导致安全阈值失守。这种现象被定义为“拒绝稀释效应”。
研究启示与防御展望
这项研究颠覆了“更多推理等于更强安全”的传统认知。相反,过长的推理链可能成为攻击者的突破口,特别是在专门优化长链推理的模型中。
现有的基于提示修补的防御策略显得力不从心。有效的解决方案可能需要将安全监控深度集成到推理过程中,包括跨层激活监控、拒绝信号强化,以及在长推理过程中持续关注潜在威胁。
这一发现为AI安全研究开辟了新方向,强调需要在模型能力提升与安全保障之间找到更精细的平衡点。
想获取更多AI最新资讯与智能工具推荐, 欢迎访问 👉 AI Tools Nav ——优质的 AI导航平台 与 AI学习社区
本文来源:机器之心
原文链接:https://www.jiqizhixin.com/articles/39e47cdd-937a-4ffa-b62c-de57842686cb





