北京人形机器人开源Pelican-VL 1.0:DPPO训练突破多模态理解,性能逼近闭源系统
北京人形机器人开源Pelican-VL 1.0:DPPO训练突破多模态理解,性能逼近闭源系统
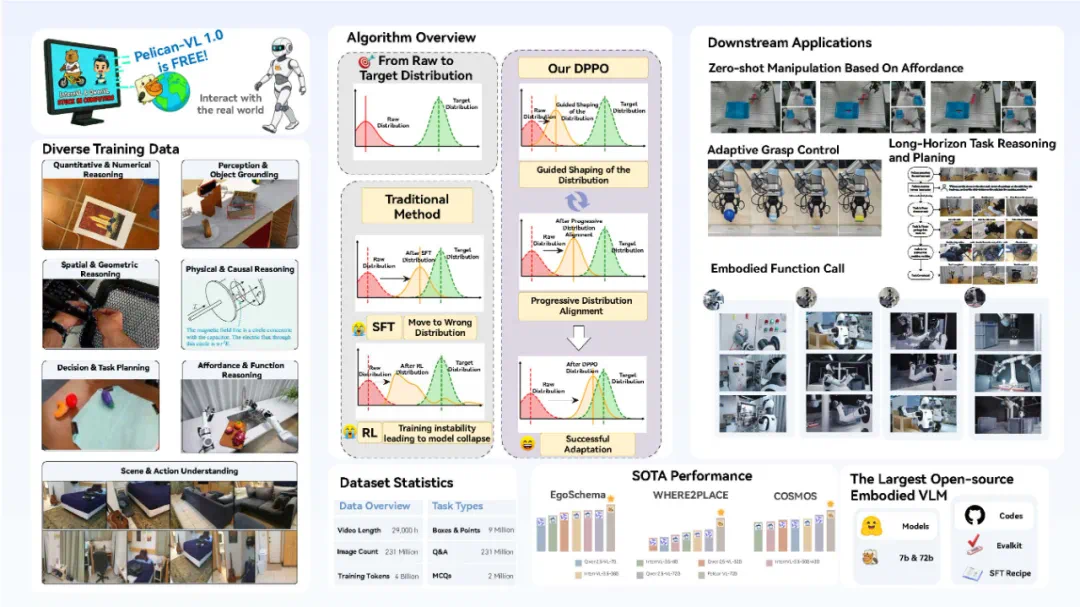
2025年,国内具身智能领域迎来研发热潮,开源视觉语言模型(VLM)技术达到新的高峰。11月13日,北京人形机器人创新中心正式发布了具身智能VLM模型——Pelican-VL 1.0,该模型提供7B和72B两种参数规模,被誉为“规模最大的开源具身多模态大脑模型”。

- 项目官网:https://pelican-vl.github.io/
- GitHub仓库:https://github.com/Open-X-Humanoid/pelican-vl
- Huggingface平台:https://huggingface.co/collections/X-Humanoid/pelican-vl-10
- ModelScope平台:https://modelscope.cn/collections/Pelican10-VL-1036b65bbdfe46
据官方技术文档显示,Pelican-VL 1.0的核心优势体现在海量数据整合与自适应学习机制的深度融合。模型在由超过1000块A800 GPU构建的计算集群上进行训练,单次检查点训练消耗超过50,000 A800 GPU小时。研发团队从原始数据中精炼出包含数亿token的高质量元数据作为训练基础。在基准测试中,模型性能提升达20.3%,超越同类开源模型10.6%。测试结果表明,其平均性能已超过GPT-5和Google Gemini等闭源模型系列,成为当前具身性能最强的开源多模态大模型。
DPPO训练范式:实现VLM快速高效提升
Pelican-VL的学习机制可类比为勤奋的学生:每个训练循环都遵循“观察视频-自主练习-发现错误-纠正提升”的流程。这一突破性进展得益于北京人形团队创新性地采用了“刻意练习”DPPO(Deliberate Practice Policy Optimization)训练范式。
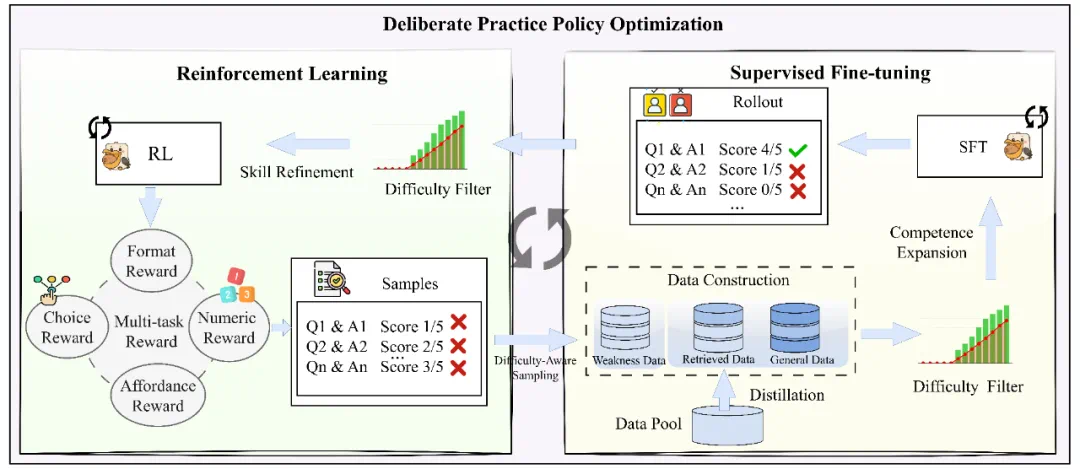
DPPO模仿人类元认知学习方式,通过强化学习(RL)探索模型弱点、生成失败样本,再进行针对性监督微调(SFT),实现模型的持续自我纠错和迭代进步。如同学生在错题后总结经验,Pelican-VL能在训练中发现“知识盲区”并进行补强,从而持续提升在视觉-语言和具身任务中的表现。这种机制使模型能更精准地理解图像内容、语言指令和物理常识,在时空推理和动作规划方面取得重大突破。
具体而言,DPPO框架包含两个核心阶段:强化学习(RL)和监督微调(SFT)。RL阶段通过多样化奖励机制和难度筛选,自动识别模型薄弱环节并快速提升能力。随后进入SFT阶段,针对弱点数据进行知识扩展和模式对齐,通过蒸馏和数据构建进一步巩固模型能力。整个过程采用难度感知采样与滚动日志记录,实现RL与SFT的迭代循环,确保模型在快速学习新技能的同时保持稳定性和全面性。
借助DPPO,Pelican-VL实现了20.3%的性能飞跃,成为同类具身模型中性能最强者。在以下关键能力方面实现显著提升:
- 多模态理解与推理能力:Pelican-VL能同步处理视觉和文本输入,训练过程中使用了海量图像、视频及跨模态标注数据。不仅能精确识别物体,还能基于场景进行物理推理、空间关系分析和功能预测。例如,在封闭厨房或商超环境中,能够识别果蔬摆放位置、柜台布局等,并据此规划物品取放动作。
- 时空认知能力:模型训练包含数万小时视频和动态场景问答数据,使其具备连续时序理解能力。在处理视频帧时,Pelican-VL能捕捉物体移动轨迹、操作步骤的时间顺序,从而对复杂连续任务序列做出合理推断,如判断“先移动哪个物品再操作下一个”。
- 具身交互能力:在物体抓取、导航、协作等机器人任务中,Pelican-VL不仅能理解任务目标,还能输出细化动作步骤并评估每步可行性。这意味着在接收指令后,模型能设计机器人关节运动轨迹、抓取点和操作策略。其多任务能力覆盖抓取、导航、人机交互等多样化应用场景,展现出强大的跨任务泛化性能。
- 自我纠错与迭代学习:依托DPPO循环训练,Pelican-VL具备“自我纠错”特性。每轮强化学习后,模型会自动生成新的挑战性样本并进行再训练,如同持续练习和复盘。随着训练推进,模型弱点被逐步修正,能力持续提升。这种“刻意练习”学习范式使Pelican-VL在迭代中不断进步,最终达到与顶级闭源系统相当的表现水平。
开源“大脑”:加速产业应用落地
这些技术改进在实际应用中展现出显著价值。北京人形团队在多项真实具身任务测试中验证:在需要调整握力抓取软物体的触觉操控任务中,Pelican-VL成功实现闭环预测与实时调节;在以“可供性”为核心的物体搬运策略中,模型能零样本生成可行操作方案;在长程任务规划方面,单一“大脑”能协调多台机器人完成级联任务。总体而言,研究论文报告显示,相较于基线模型,Pelican-VL在空间理解和时间推理等能力上实现显著提升,在多个公开基准测试中超越部分100B量级的开源系统,甚至接近某些闭源模型水平。
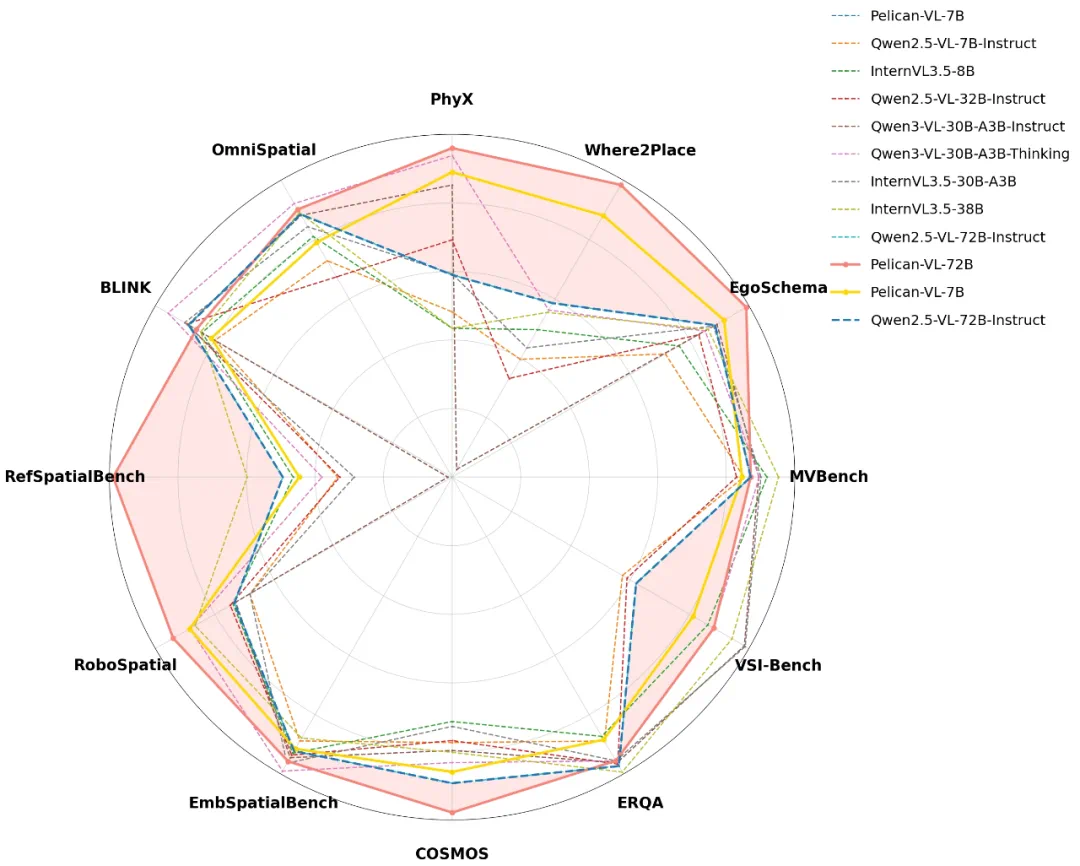
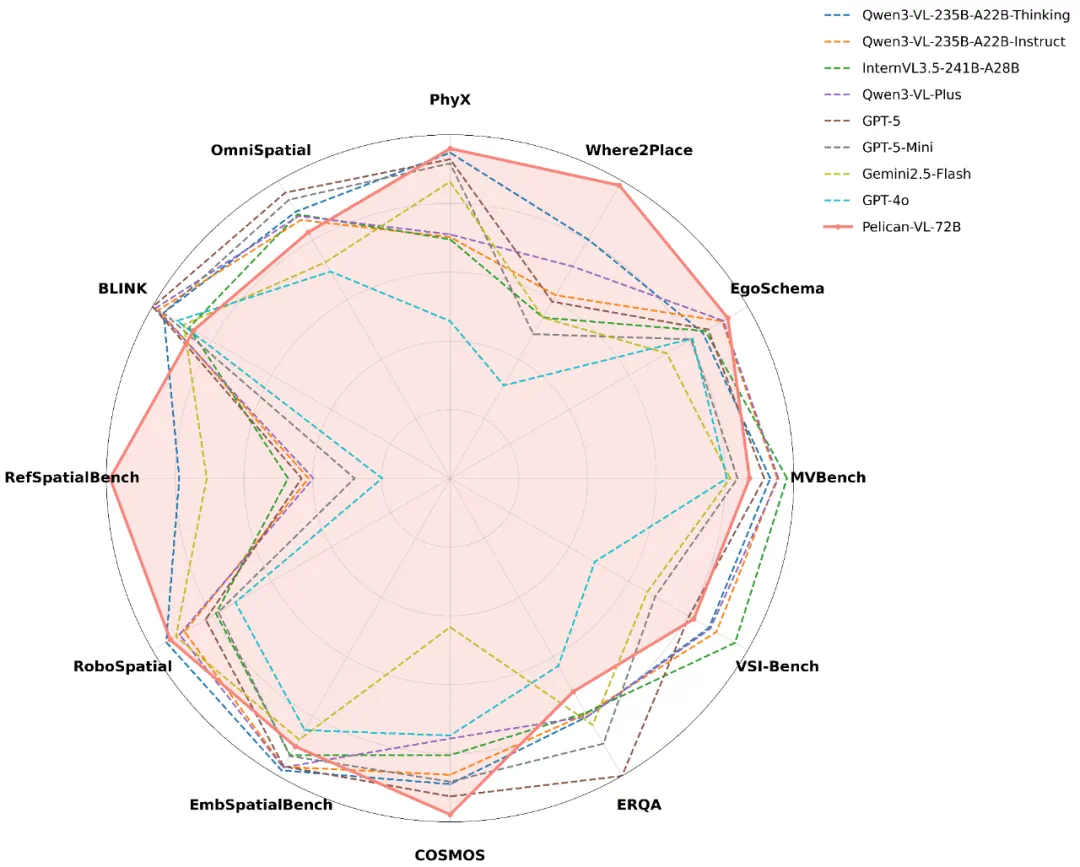
同时,团队在九维度具身智能分类体系中对Pelican-VL各项技能进行评估,雷达图显示各项指标分布均衡,关键维度表现突出。
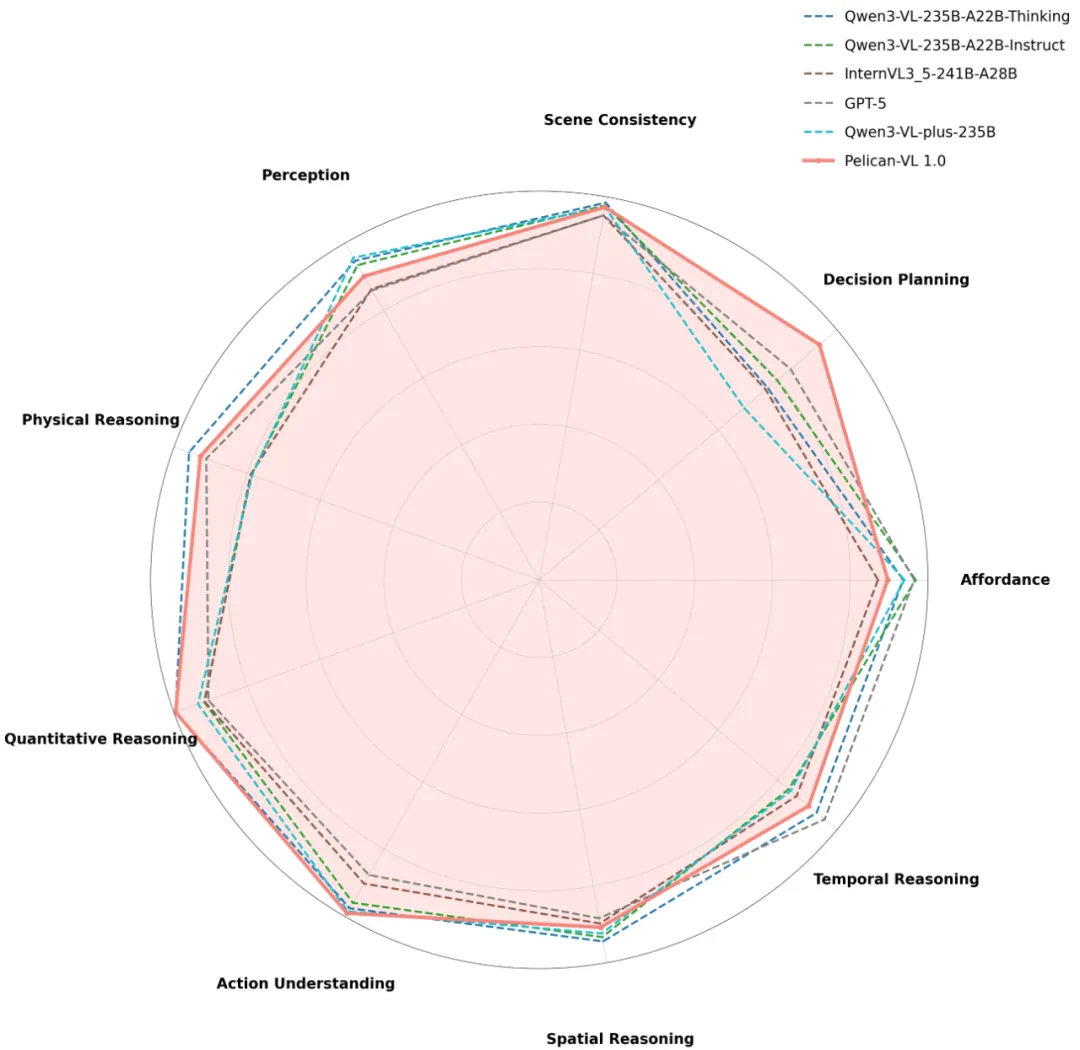
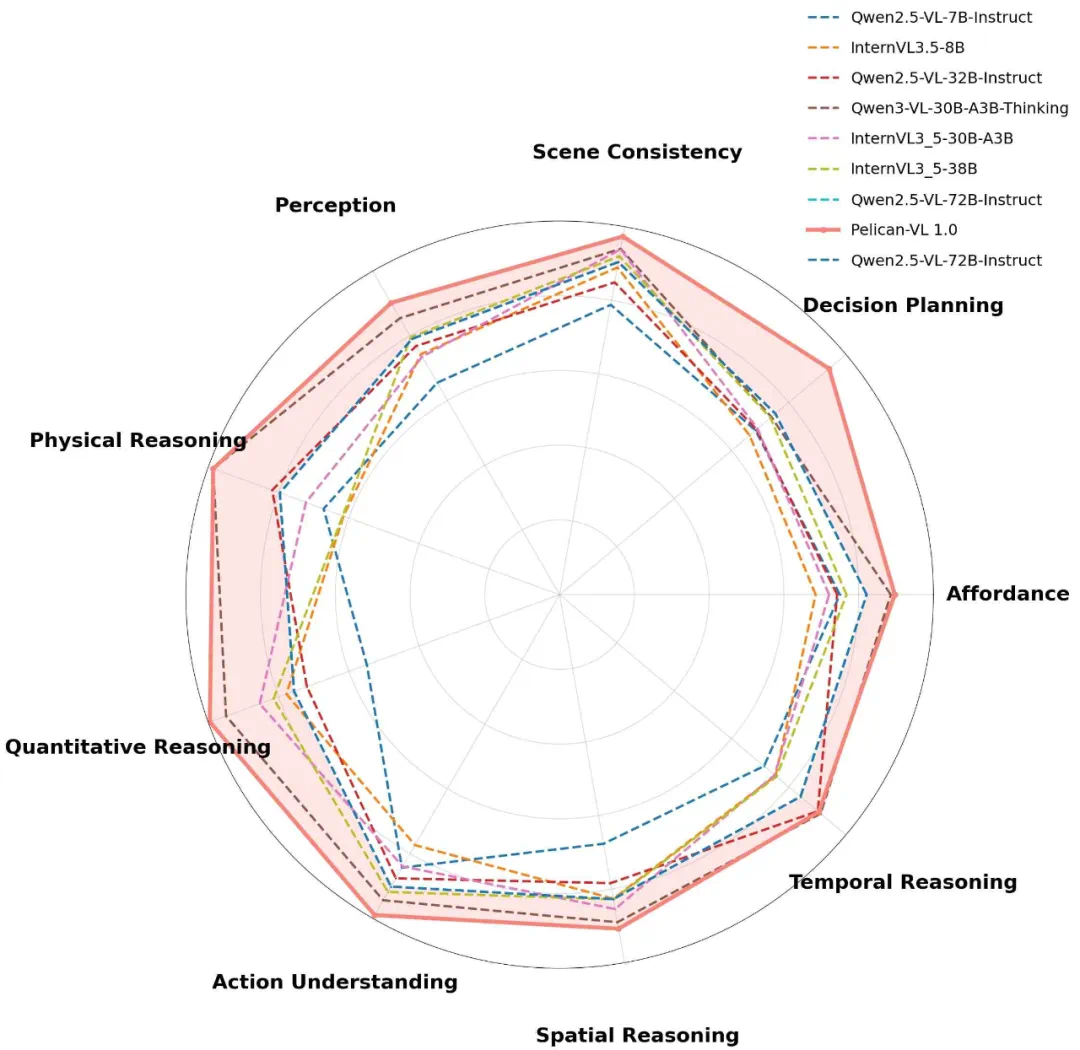
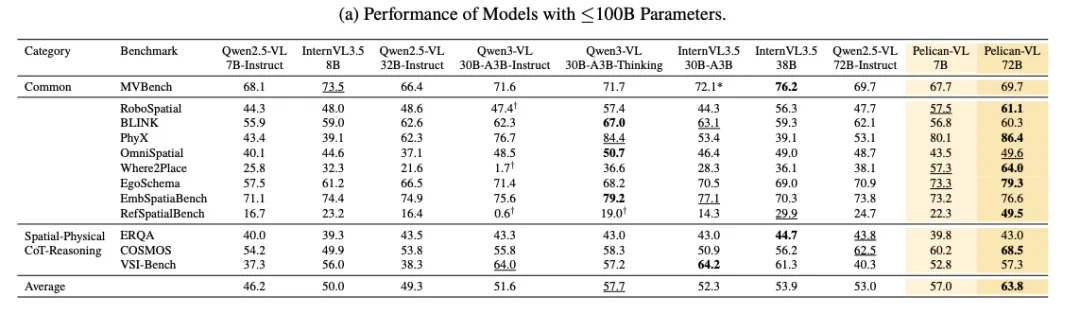
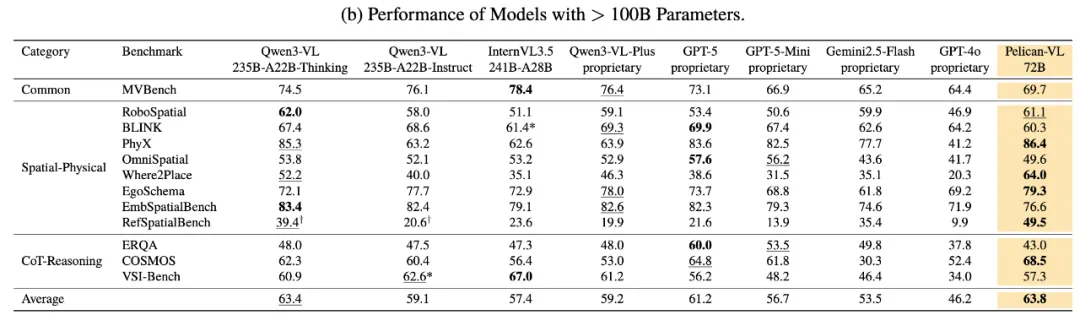
注:粗体数字和带下划线数字分别表示最佳和次佳结果。符号“†”标记的结果与官方报告存在差异或异常偏低,可能是由于官方评估使用模型专属提示词(模型对提示词较为敏感),而本研究结果基于统一实验方案以确保公平对比。星号“*”表示结果来源于官方渠道。黄色单元格标记本文提出的Pelican-VL 1.0模型。
对产业界和科研领域而言,Pelican-VL具有双重现实意义:首先,它提供了“视觉理解→长期规划→物理操作”串联的可复用训练范式,降低了在机器人中应用VLM的技术门槛;其次,团队选择开源基础模型和推理代码,意味着其他实验室或企业可基于此“大脑”进行定制化训练,加速实际应用探索。
北京人形团队在讨论中指出,尽管取得显著进步,但高质量具身数据的稀缺性、评测基准的局限性以及如何在人类环境中安全可靠地部署,仍是未来需要直面挑战。
为帮助读者具象化理解这项研究的影响:想象家庭助手机器人不仅能识别碗盘位置,还能判断“这个杯子适合盛汤吗?”“这个苹果该如何轻拿轻放避免挤压损坏?”并在实际操作失败后自主学习和改进——Pelican-VL正是朝着这个方向迈出的重要一步。
国际模型对比:技术路线与应用场景分析
Pelican-VL代表了国内具身智能的端到端解决方案,与国外知名模型在技术策略和应用场景上各具特色。
国外AI巨头技术布局
英伟达Cosmos-Reason1:2025年3月发布,专为物理智能设计的双尺寸多模态大模型(8B和56B)。在空间、时间和基础物理三大常识领域融合视觉与文本信息,具备强大的物理常识推理和具身推理能力。采用ViT-300M视觉编码器、Mamba-MLP-Transformer主干网络,配合多阶段训练流程(包括视觉预训练、通用与物理智能SFT、强化学习),基于1亿级多模态样本和千万级具身与物理常识数据。在物理推理、空间认知等多项基准测试中表现卓越,并开源权重与代码。
Google Gemini Robotics-ER:以具身推理为核心目标,使AI能在真实物理环境中理解、规划并决策,主要应用于机器人领域。具备多模态推理能力,能处理物体检测、空间理解、抓取预测和三维轨迹规划等任务,将视觉感知转化为机器人可执行的高级指令。支持多步规划和环境反馈动态调整,使用ERQA等数据集评估现实任务能力。此外,Google探索“内心独白”机制,使机器人在动态环境中能自主思考、实时调整,实现高鲁棒性具身智能。相关技术已集成于Google AI Studio、Gemini API和Vertex AI,为自动化生产、导航、操作等机器人实际应用提供支持。
GPT-5:作为通用视觉-语言大模型,具备强大的图像理解和跨模态推理能力,但设计初衷并非专注于物理执行。GPT-5能回答视觉问题、生成图像描述,但缺乏与机器人硬件对接的控制层。
与国外闭源模型相比,Pelican-VL基于国内开源模型进行预训练,使用较少数据和训练资源即达到相当甚至更优的性能,整体数据利用率达到其他模型的10-50倍。此外,作为开源模型,Pelican-VL能够赋能全球具身行业。在国内市场,Pelican-VL同样是性能最优的具身智能模型,相比国内同类模型平均性能提升超过10%。
展望未来
从构建“具身天工”和“慧思开物”这一硬一软通用平台开始,到如今通过算法推动行业研发、以数据利用率加速模型迭代、以开源策略夯实产业应用基础,北京人形始终以宏观视角探索具身智能发展路径。这种“平台+生态”的布局策略,有望促进技术闭环与数据孤岛的打破,推动具身智能从实验室的单点突破走向产业链协同的规模化发展。
随着越来越多企业借助开源工具降低研发门槛,真实场景数据持续反哺模型进化,具身智能有望加速渗透工业、家庭、物流等多元化场景,最终使机器人真正具备“感知-思考-行动”的通用智能能力。
想获取更多AI最新资讯与智能工具推荐, 欢迎访问 👉 AI Tools Nav ——优质的 AI导航平台 与 AI学习社区
本文来源:机器之心
原文链接:https://www.jiqizhixin.com/articles/a3a92285-c1d1-49e4-af22-f0c2efc6aa2d





