字节跳动发布Depth Anything 3:简化Transformer实现高效3D视觉建模
字节跳动发布Depth Anything 3:简化Transformer架构实现高效3D视觉建模
如今,仅需一个基于深度光线表示训练的简单Transformer模型,就能实现强大的3D视觉能力。
这项突破性研究揭示了一个重要发现:当前大多数3D视觉研究存在过度复杂化的问题。
上周五,AI研究社区被一篇关于3D建模的创新论文引爆热议。经过长达一年的深入探索,字节跳动研发团队正式推出Depth Anything 3(DA3),这项技术将单目深度估计扩展至任意视角场景,使计算机系统具备了接近人类水平的环境空间感知能力。

核心资源链接:
- 研究论文:https://arxiv.org/abs/2511.10647
- 项目主页:https://depth-anything-3.github.io
- 开源代码:https://github.com/ByteDance-Seed/Depth-Anything-3
- 在线演示:https://huggingface.co/spaces/depth-anything/depth-anything-3
在追求最小化建模复杂度的过程中,DA3团队获得了两个关键技术洞见:
- 标准Transformer架构(如DINO)足以胜任3D视觉任务,无需专门定制复杂网络结构
- 单一深度射线表示法可替代繁琐的多任务3D处理流程
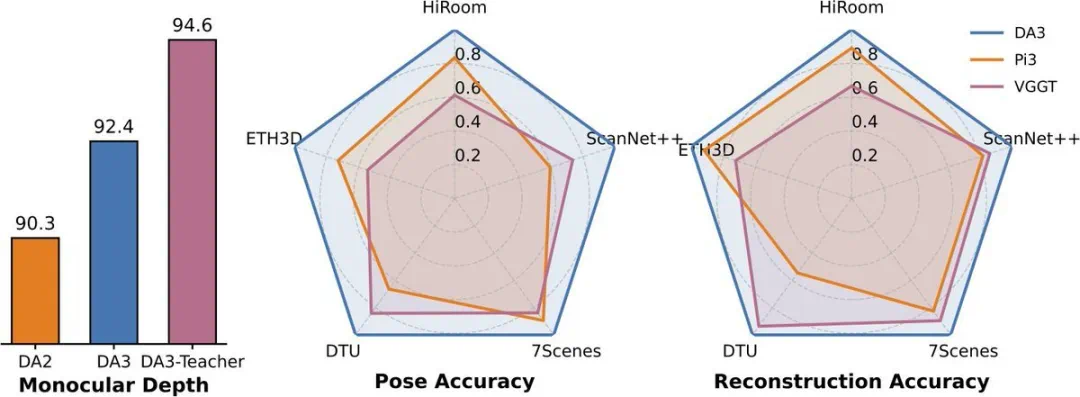
令人惊叹的是,这种简洁的方法在姿态估计任务中比当前最优技术提升了44%的精度,在几何估计方面也实现了25%的性能飞跃。这一成果不禁让人思考:3D视觉技术原来可以如此简洁高效?

纽约大学计算机科学助理教授、知名人工智能学者谢赛宁对此给予高度评价。他将论文系列比作电影续作,通常后续作品会更加复杂却未必更精彩,但Depth Anything系列完全打破了这一规律。Bingyikang领导的团队每次迭代都能让技术变得更加简洁且易于扩展。
谢教授深刻指出:「Depth Anything 3的核心贡献在于证明:一个强大的表示编码器配合深度光线预测目标,就足以在众多任务中获得可靠且通用的空间感知能力。」他进一步阐述了对计算机视觉领域的独到见解:「视觉并非孤立任务的简单叠加,而是一种独特的认知视角——它关乎如何对连续感官数据进行建模,构建世界的层次化表征,并逐步迈向类人智能水平。」
技术架构深度解析
Depth Anything 3(DA3)是一个能够根据任意数量视觉输入预测空间一致性几何形状的先进模型,无论相机位姿是否已知。为实现极简化建模,该研究确立了双重核心原则:采用标准Transformer架构作为骨干网络,避免特殊化设计;使用单一深度光线预测目标,规避复杂多任务学习。
目前DA3已发布三个专业系列:核心DA3系列、单目测量估计系列和单目深度估计系列,满足不同应用场景需求。
创新方法论
DA3将几何重建任务构建为密集预测问题。对于给定的N张输入图像,模型经过专门训练可输出对应的深度图和光线图,确保每个输出都与输入图像像素精确对齐。该架构以预训练视觉Transformer为核心骨干,充分发挥其卓越的特征提取能力。
为处理任意数量视图,研究团队引入了突破性的输入自适应跨视图自注意力机制。该模块在前向传播过程中动态重排token序列,实现跨视图的高效信息交互。最终预测阶段采用创新的双DPT头设计,通过处理同一组特征但使用不同融合参数,联合输出深度值和光线值。为增强实用性,模型还可通过简易相机编码器选择性整合已知相机姿态,适应多样化实际应用场景。
训练策略精要
DA3模型采用师生训练范式,统一整合多样化训练数据源,包括真实世界深度相机采集数据、3D重建数据和合成数据。针对真实世界深度数据质量不稳定的挑战,团队开发了基于伪标注的优化策略——使用合成数据训练强健的单目深度模型,为所有真实数据生成高密度、高质量的伪深度图。这种方法在保持几何精度的同时,显著提升了标签细节完整度。
为建立科学的评估体系,团队构建了全新的视觉几何基准,涵盖相机姿态估计、任意视图几何(TSDF重建)和视觉渲染三大维度。DA3在全部10项评测任务中均刷新纪录,相机姿态精度比之前最优技术VGGT平均提升35.7%,几何精度提升23.6%。在单目深度估计任务中,DA3超越了前代Depth Anything V2,同时在细节还原和鲁棒性方面表现相当。
多元化应用场景
Depth Anything 3展现出多领域应用潜力,具体包括:
- 视频场景重建:DA3能够从单视图到多视图的任意数量输入中恢复视觉空间结构,演示展示了模型从复杂视频流中重建视觉空间的卓越能力

- 大规模场景SLAM:精确的视觉几何估计显著提升同步定位与地图构建性能。量化结果表明,在大规模环境中,仅用DA3替换VGGT-Long中的VGGT组件(形成DA3-Long)即可大幅降低漂移误差,效果甚至优于需要48小时以上处理时间的COLMAP系统
- 前馈3D高斯估计:通过冻结整个主干网络,在多个数据集上专门训练DPT头部来预测3D高斯溅射参数,模型实现了强大且泛化能力出色的新颖视图合成功能
- 多摄像头空间感知:DA3能够从车辆多个视角同步获取图像,生成稳定且可融合的深度图,极大增强自动驾驶车辆的环境理解能力,该技术同样适用于机器人导航领域
Depth Anything 3发布后,迅速获得开发者社区积极响应,众多技术专家表示将把这一简洁高效的设计理念融入各自项目。这种以简化实现强大的技术路线,正是产业界迫切需要的落地方向。
如需深入了解技术细节,请参阅完整技术报告。
参考资料来源:
https://x.com/bingyikang/status/1989358278346977486
https://x.com/sainingxie/status/1989423686882136498?s=20
想获取更多AI最新资讯与智能工具推荐, 欢迎访问 👉 AI Tools Nav ——优质的 AI导航平台 与 AI学习社区
本文来源:机器之心
原文链接:https://www.jiqizhixin.com/articles/4555c856-3085-48c9-9ef8-d6ae3b04ce55





