ByteRobust发布:高效故障诊断与容错机制提升大规模语言模型训练稳定性与效率
ByteRobust革新LLM训练:高效故障诊断与容错机制显著提升大规模模型训练稳定性
在当今人工智能领域,GPU已成为大型语言模型训练的核心计算基础。随着模型规模的指数级增长,训练所需的GPU数量已突破万块大关,且持续扩张态势明显。以LLaMA 3为例,这个4050亿参数的巨型模型预训练过程动用了16,384块NVIDIA H100 GPU,耗时长达54天。字节跳动此前也使用12,288块GPU成功训练了1750亿参数模型,而xAI更是建立了配备10万块GPU的超级集群,将训练规模推向新的高度。
然而,资源规模的急剧扩张带来了不可避免的技术挑战——系统故障频发成为常态。从CUDA运行错误、NaN数值异常到任务无响应挂起,各类故障严重威胁着训练过程的稳定性。Meta公司曾公开披露,在16,000块GPU上训练大模型时,硬件故障平均每2.78小时就会发生一次,凸显了问题的严峻性。
当前业界主流的LLM训练故障处理方案普遍采用"故障即停止"模式,依赖事后日志分析和退出码评估,或通过独占集群进行压力测试。一旦确定故障根源,训练任务需要重新调度资源与并行配置,并从远程文件系统加载TB级别的检查点数据。这套"停止-诊断-恢复"流程耗费巨大,中断时间从数小时到数天不等。随着模型规模扩大导致的故障频率上升,有效训练时间比率面临严重制约。
针对这一行业痛点,字节跳动最新发布的论文详细介绍了其创新性LLM训练基础设施ByteRobust,为大规模模型训练提供了全新的解决方案。这一系统设计让我们得以窥见字节跳动如何稳健训练其豆包大模型的技术细节。

- 研究论文:Robust LLM Training Infrastructure at ByteDance
- 论文链接:https://arxiv.org/abs/2509.16293
这项突破性研究由六位共同第一作者合作完成:Borui Wan、Gaohong Liu、Zuquan Song、Jun Wang、Yun Zhang和Guangming Sheng。
ByteRobust:重新定义稳健的LLM训练基础设施
ByteRobust是字节跳动基于生产环境实践经验构建的创新型训练平台,其核心设计理念围绕"稳健性"展开。系统的关键目标是通过最小化非生产时间实现高效事件诊断与处理,从而在大规模LLM训练中达成极高的有效训练时间比率。该系统专门设计用于监控和管理LLM训练全生命周期,实现大规模自动化高效处理各类训练事件。
ByteRobust采用双平面架构设计,由控制平面和数据平面两大核心组件构成。
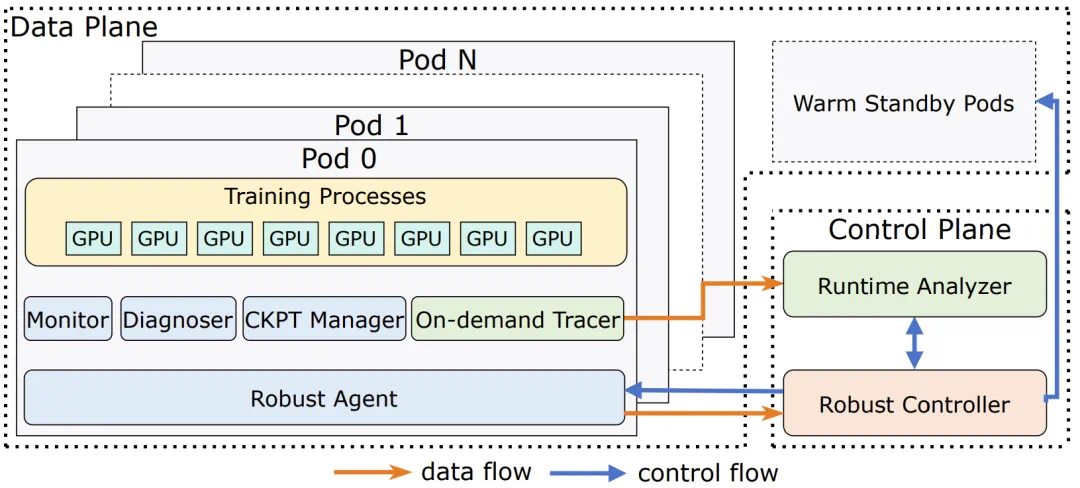
ByteRobust系统架构示意图
控制平面:智能协调与决策中枢
控制平面运行于训练任务外部,负责协调稳健的事件处理策略,包括异常检测、故障定位和恢复操作触发。
Robust Controller作为核心协调器,构建了自动化故障缓解框架,利用实时监控和"停止-诊断"机制处理大多数事件。为实现可控快速恢复,系统在无需机器驱逐时采用"原地热更新"机制重启训练;当需要驱逐机器时,则请求经过自检预验证的"温备用"机器恢复任务。
Runtime Analyzer通过聚合训练Pod的堆栈跟踪,智能隔离和驱逐可疑机器,有效解决任务挂起和性能下降问题。
数据平面:精细化执行与监控
数据平面驻留在每个训练Pod内部,集成监控、诊断、检查点管理和堆栈跟踪捕获等模块,提供实时可观测性、中断即时诊断、快速检查点回滚和按需聚合分析能力。
Robust Agent守护进程在每个训练Pod中运行,处理控制平面信号并管理四大关键子模块:
- 监控器:收集多维度数据检测异常值,支持实时检查并在异常时触发聚合分析
- 诊断器:任务暂停后运行专业基准测试和测试套件,实现复杂故障深度诊断
- 按需追踪器:捕获训练进程堆栈跟踪并上传至运行时分析器
- 检查点管理器:执行异步检查点设置,将备份跨并行组存储至CPU内存和本地磁盘,最小化恢复成本
与传统GPU管理和容错系统不同,ByteRobust将LLM训练任务清单扩展至细粒度进程管理级别,充分利用运行时信息进行故障检测和快速恢复。
创新设计理念:三大核心技术突破
1. 优先快速隔离,放弃精确定位
ByteRobust采用"快速故障隔离优先"策略,而非耗时精确定位。在涉及数千块GPU的超大规模训练中,精确定位故障会导致大量GPU闲置。为最大化有效训练时间比率,系统结合轻量级实时检测与分层"停止-诊断"机制,以最小开销快速识别故障机器。
当标准方法无法解决问题时,ByteRobust应用数据驱动方法,对运行时堆栈跟踪进行聚类分析,在定义的故障域内隔离可疑机器,宁可"过度驱逐"也不追查确切根源。
2. 人性化设计:主动应对人为错误
与传统深度学习训练不同,长达数月的LLM训练涉及数据、算法和工程代码持续更新,显著增加系统脆弱性。认识到人为错误是不可避免的故障来源,ByteRobust构建了自动化容错框架。
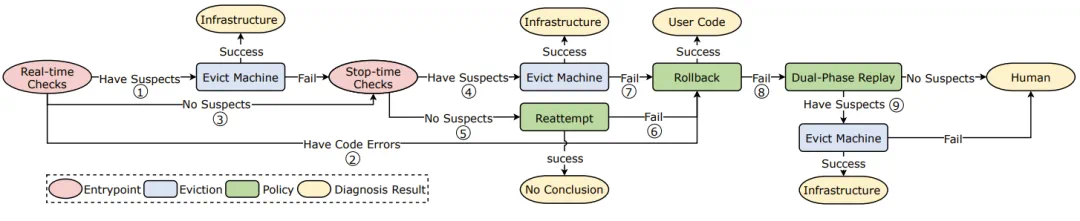
ByteRobust自动化容错机制工作流程
该框架整合了即时检测常见错误的实时检查、深入分析复杂故障的"停止-诊断"、从瞬时故障恢复的原地重试、从缺陷用户代码恢复的代码回滚,以及解决SDC等极端情况的回放测试。
通过"延迟更新"方法,用户代码变更可与确定性故障恢复过程合并,巧妙利用故障必然性和高频率特性。
3. 恢复过程可控性保障
硬件缺陷、软件错误和机器性能退化都是故障来源,因此在代码升级和恢复过程中确保稳定性至关重要。对于不改变机器分配的变更,系统采用"原地热更新"机制保留运行时环境并简化诊断。
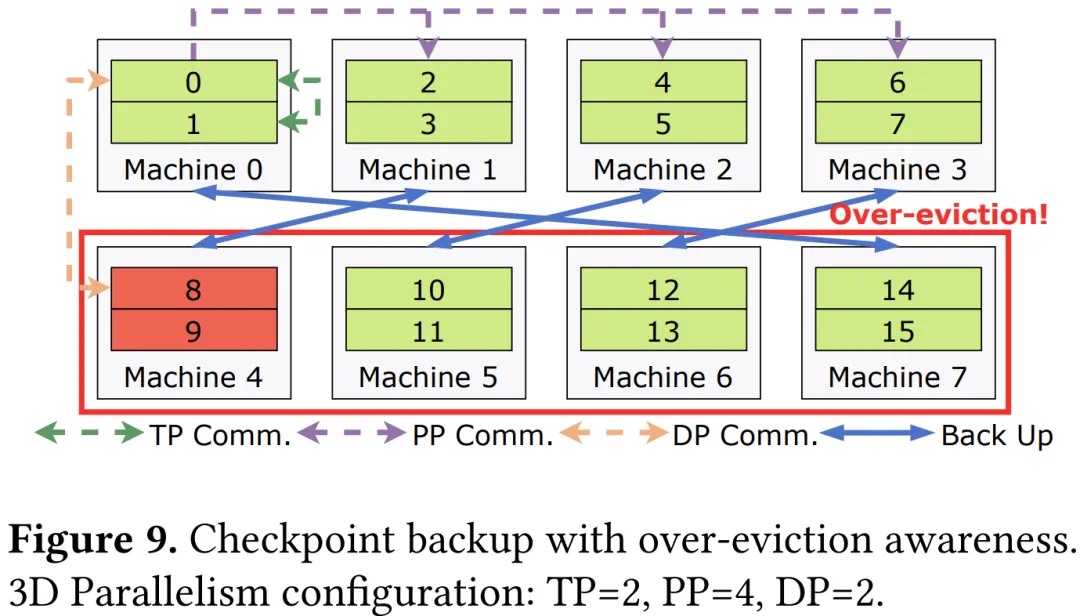
为确保可控快速恢复,ByteRobust利用预先配置的"温备用"机器,这些机器交付前执行自检,避免整个任务重新调度。检查点模块通过将备份分布在不同并行组中,与故障域紧密结合,消除对远程文件系统依赖,实现快速重启。
实际部署成效:数据说话
ByteRobust已在实际生产环境中部署超过一年,支撑字节跳动高性能生产GPU集群的内部LLM训练。系统显著减少事件检测时间,通过自动容错框架和聚合分析高效解决事件。
在三个月监测期内,ByteRobust通过自动化容错训练框架成功识别38,236次显式故障和5,948次隐式故障。
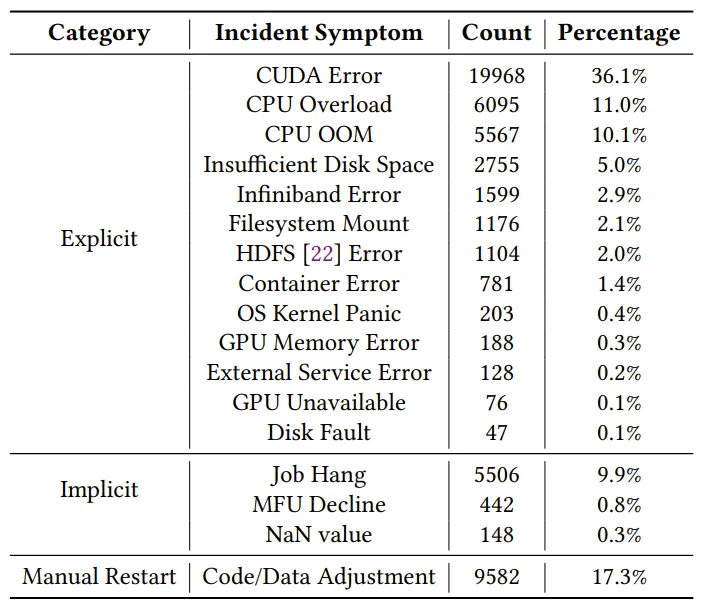
三个月期间训练事故统计数据,覆盖778,135个LLM训练任务
在16,384块GPU上的微基准测试显示,温备用和热更新机制在恢复速度上分别实现10.87倍和11.04倍提升。
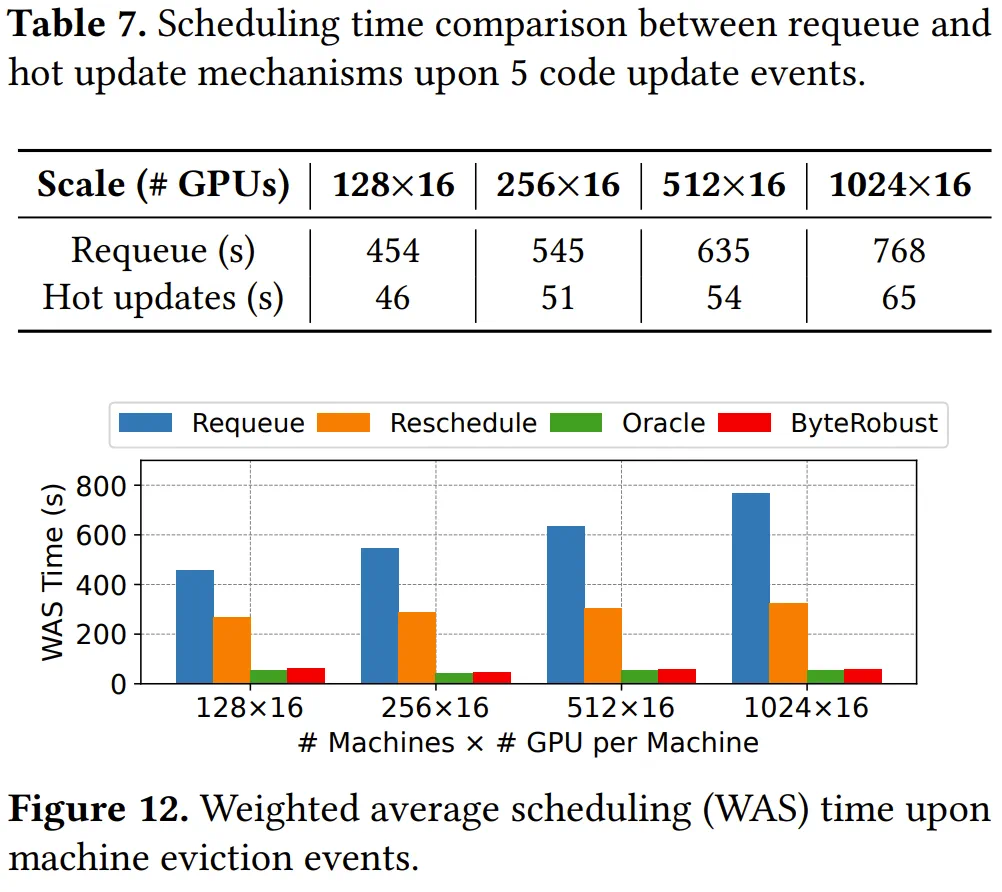
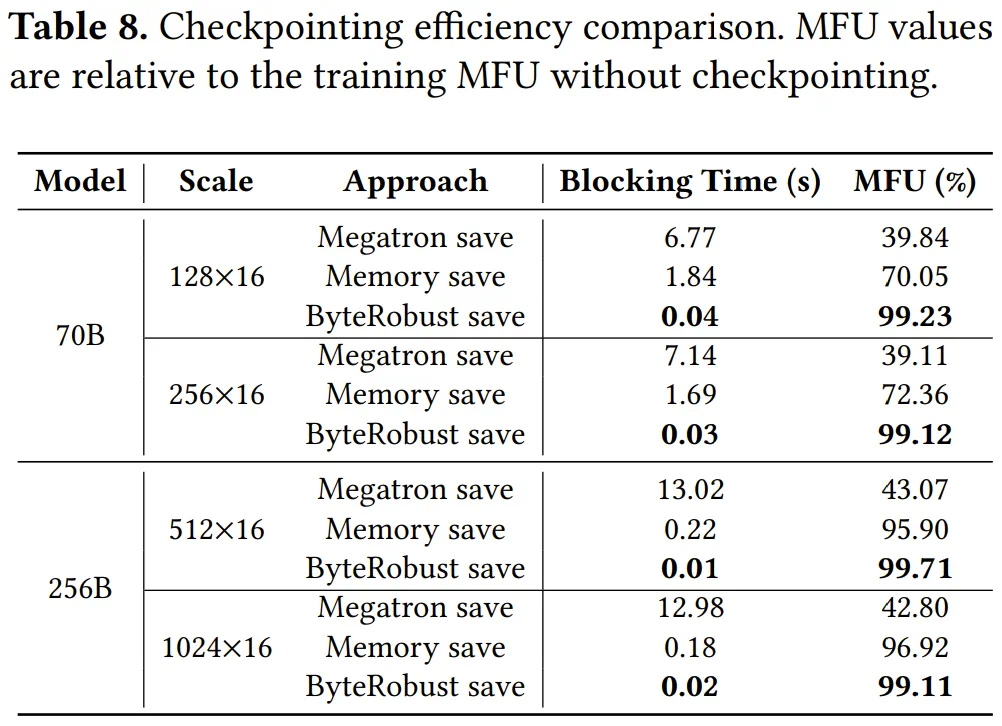
ByteRobust高效检查点机制实现"每步检查点",开销低于0.9%,大幅加速故障切换过程。
部署实验证明,在为期三个月、使用9,600块GPU的密集模型训练任务中,ByteRobust实现高达97%的有效训练时间比率。
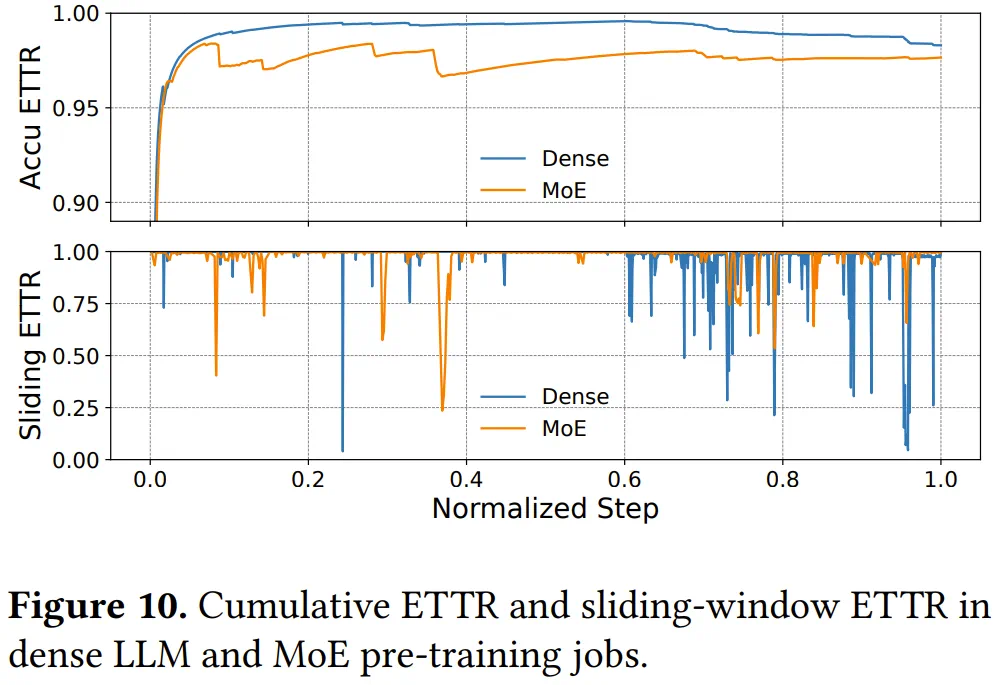
累计ETTR和滑动窗口ETTR性能指标
在为期一个月的MoE模型训练任务中,ByteRobust同样表现卓越。随着训练推进,两个任务的相对模型浮点运算利用率持续增长。训练期间,字节跳动最初部署基础版预训练代码,随后持续优化学习过程和计算效率。
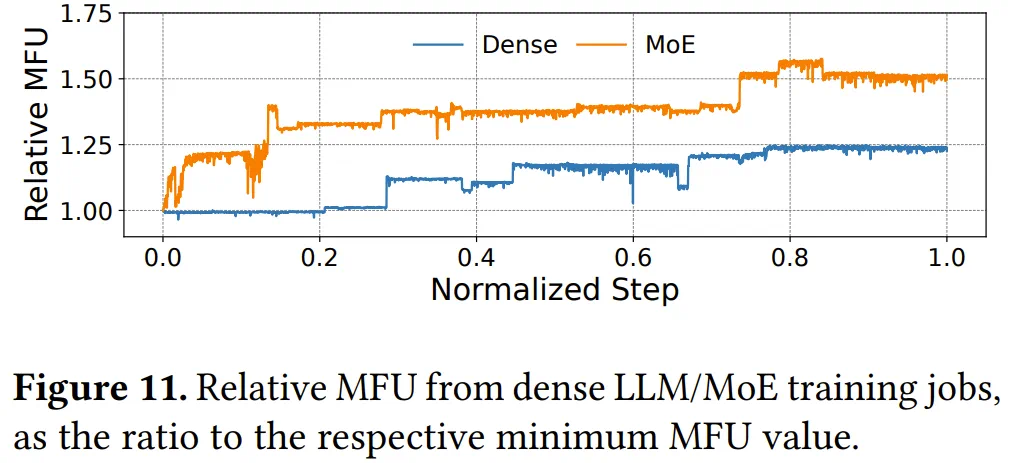
图表中MFU曲线的每次跃升表明更高效训练代码版本通过ByteRobust热更新机制成功部署,同时对ETTR影响微乎其微。与初始运行时相比,密集模型和MoE任务分别实现1.25倍和1.58倍的MFU提升。
观察发现,与密集模型相比,MoE训练的ETTR相对较低。密集模型训练性能通常经社区充分优化,而MoE训练涉及大量自定义优化,如GPU内核调优、计算与通信重叠和负载均衡策略。这些优化虽能提高训练效率并展现更高MFU,但也引入额外复杂性,增加代码回滚和手动重启可能性。
更多技术细节和研究发现请参阅原始论文。
想获取更多AI最新资讯与智能工具推荐, 欢迎访问 👉 AI Tools Nav ——优质的 AI导航平台 与 AI学习社区
本文来源:机器之心
原文链接:https://www.jiqizhixin.com/articles/7d378b00-067e-4083-8b6b-307ed5de1ad0





