AI驱动LDBT范式重构生物设计:机器学习优化蛋白质合成
AI驱动LDBT范式重构生物设计:机器学习优化蛋白质合成

传统合成生物学遵循设计-构建-测试-学习循环。随着机器学习技术的突破性进展,研究人员提出颠覆性理念:让「学习」环节前置于「设计」阶段。
在当代合成生物学实验室中,科研人员遵循着一套标准操作流程:基因序列设计、质粒构建、菌株转化、功能验证——这一完整链条被业界称为DBTL循环(Design-Build-Test-Learn)。这套方法论已成为近二十年来生物工程领域的黄金标准,通过系统化、迭代式的工程框架显著简化了生物系统的构建过程。
尽管机器学习技术为蛋白质与代谢途径设计开辟了新路径,但受限于蛋白质功能表征等关键技术瓶颈,整体研发效率仍有待提升。在传统DBTL循环的最终环节「学习」阶段,机器学习方法之所以占据主导地位,并非因其完全取代了物理模型,而是由于现有生物物理模型在处理生物分子复杂性时面临计算成本高昂和应用范围有限的挑战。
基于此,研究团队提出革命性构想——将学习环节前置。
这一创新思路源自美国德克萨斯大学奥斯汀分校、西北大学与斯坦福大学的联合研究团队,他们正式提出LDBT新范式——Learn→Design→Build→Test循环体系。
这项突破性研究成果以《LDBT instead of DBTL: combining machine learning and rapid cell-free testing》为题,已于2025年11月5日发表于国际顶级期刊《Nature Communications》。

论文链接:https://www.nature.com/articles/s41467-025-65281-2
学习引领设计新纪元
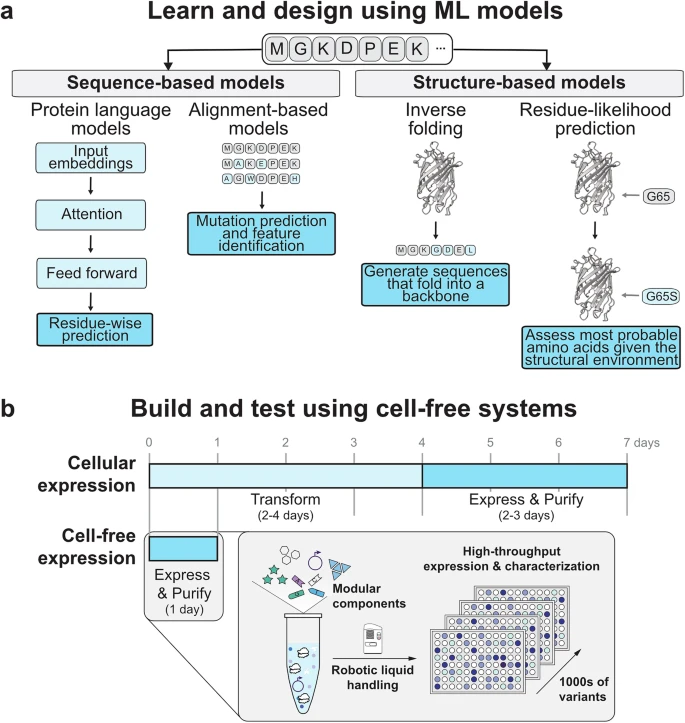
以ESM和ProGen为代表的蛋白质语言模型,通过在全进化树中嵌入蛋白质序列的进化关系进行训练,已具备预测有益突变和推断蛋白质功能等核心能力。
尽管机器学习技术已显著增强零样本设计策略等前沿领域,传统DBTL循环仍需要多轮迭代才能积累有效知识,其中构建-测试环节的效率瓶颈尤为突出。本应在该阶段获取的学习数据往往早已完成训练。因此,研究团队借鉴零样本预测理念,通过LDBT范式对循环顺序进行重构。
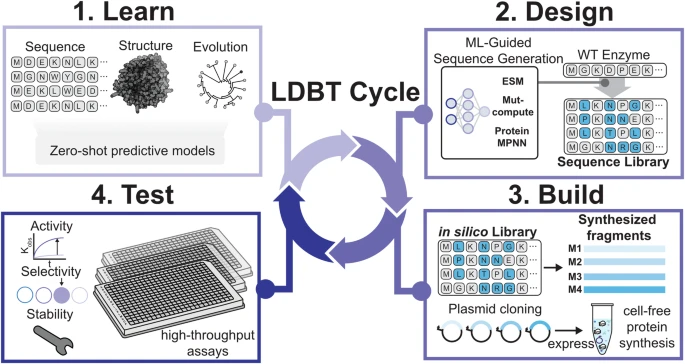
在新范式下,研究流程实现双重革新:首先,借助深度学习模型(如蛋白质语言模型ESM-2、结构设计模型ProteinMPNN),人工智能可在无明确模板条件下自主生成全新蛋白质序列与结构预测;其次,基于模型输出结果,研究人员可筛选最优方案,并利用结构建模工具(AlphaFold、RosettaFold)精准预测蛋白质折叠稳定性与活性位点分布,此举可将设计成功率提升近10倍。
DBTL流程的演进同样受益于技术创新。通过采用细胞裂解物等材料实现体外转录与翻译,研究人员成功规避了耗时的克隆步骤,使得表达蛋白质能够直接投入使用或进行纯化处理。
人工智能代理驱动的闭环设计平台进一步扩展了研发产能。无细胞表达系统带来高通量处理能力,为构建机器学习训练所需的大规模数据集和验证计算预测提供了强大工具支撑,其中还包括解决蛋白质表达难题的关键数据。
要将这些突破性进展延伸至蛋白质工程之外,仍需在分子与途径建模等领域取得进一步突破。在重构的LDBT循环体系中,从「目标功能」到「序列设计」再到「功能性蛋白质」的完整路径,有望彻底释放生物学的全设计空间潜力。
想获取更多AI最新资讯与智能工具推荐, 欢迎访问 👉 AI Tools Nav ——优质的 AI导航平台 与 AI学习社区
本文来源:机器之心
原文链接:https://www.jiqizhixin.com/articles/8c93d8d2-06e6-4c7d-87e4-368a5c2b780c





